
Data Quality and Fuzzy Searching
IRI is now also delivering fuzzy search functions, both in its free database and flat-file profiling tools, and as available field-function libraries in IRI CoSort, FieldShield, and Voracity to augment data quality, security, and MDM capabilities. This is the first in a series of articles on IRI fuzzy search solutions covering their application to data quality improvement.
Introduction
The veracity or reliability of data of one of big ‘V’ words (along with volume, variety, velocity, and value) that IRI et al talk about in the context of data and enterprise information management. Generally, IRI defines data in doubt as having one or more of these attributes:
- Low quality, because it is inconsistent, inaccurate, or incomplete
- Ambiguous (think MDM), imprecise (unstructured), or deceptive (social media)
- Biased (survey question), noisy (superfluous or contaminated), or abnormal (outliers)
- Invalid for any other reason (is the data correct and accurate for its intended use?)
- Unsafe – does it contain PII or secrets, and is that properly masked, reversible, etc.?
This article focuses only on new fuzzy search solutions to the first problem, data quality. Other articles in this blog discuss how IRI software addresses the other four veracity problems; ask for help finding them if you can’t.
About Fuzzy Searching
Fuzzy searches find words or phrases (values) that are similar, but not necessarily identical, to other words or phrases (values). This type of search has many uses, such as finding sequence errors, spelling errors, transposed characters, and others we’ll cover later.
Performing a fuzzy search for approximate words or phrases can help find data that may be a duplicates of previously stored data. However, user input or auto correction may have altered the data in some way to make the records seem independent.
The rest of the article will cover four fuzzy search functions which IRI now supports, how to use them to scour your data, and return those records approximating the search value.
1. Levenshtein
The Levenshtein algorithm works by taking two words or phrases, and counting how many edit steps it will take to turn one word or phrase into the other. The less steps it will take, the more likely the word or phrase is a match. The steps the Levenshtein function can take are:
- Insertion of a character into the word or phrase
- Deletion of a character from the word or phrase
- Replacement of one character in a word or phrase with another
The following is a CoSort SortCL program (job script) demonstrating how to use the Levenshtein fuzzy search function:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
There are two parts that must be used to produce the desired output.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
This line calls the function fs_levenshtein, and stores the result in the field FS_RESULT. The function takes two input parameters:
- The field to run the fuzzy search on (NAME in our example)
- The string that the input field will be compared to (“Barney Oakley” in our example).
/INCLUDE WHERE FS_RESULT GT 50
This line compares the FS_RESULT field and checks if it is greater than 50, then only records with an FS_RESULT of more than 50 are output. The following shows the output from our example.
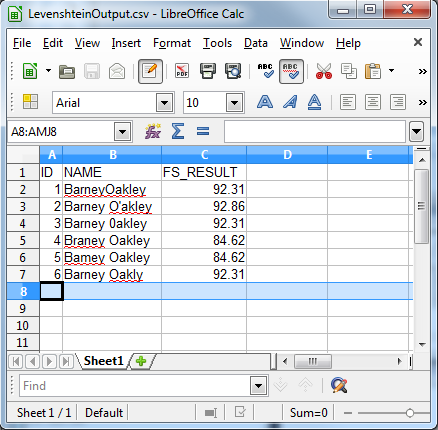
As the output shows this type of search is useful for finding:
- Concatenated names
- Noise
- Spelling errors
- Transposed characters
- Transcription mistakes
- Typing errors
The Levenshtein function is thus useful for identifying common data entry errors, too. However, it takes the longest to perform out of the four algorithms, as it compares every character in one string to every character in the other.
2. Dice Coefficient
The dice coefficient, or dice algorithm, breaks up words or phrases into character pairs, compares those pairs, and counts the matches. The more matches the words have, the more likely the word itself is a match.
The following SortCL script demonstrates the dice coefficient fuzzy search function.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
There are two parts that must be used to give us the desired output.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
This line calls the function fs_dice, and stores the result in the field FS_RESULT. The function takes two input parameters:
- The field to run the fuzzy search on (NAME in our example).
- The String that the input field will be compared to (“Robert Thomas Smith” in our example).
/INCLUDE WHERE FS_RESULT GT 50
This line compares the FS_RESULT field and checks if it is greater than 50, then only records with an FS_RESULT of more than 50 are output. The following shows the output from our example.
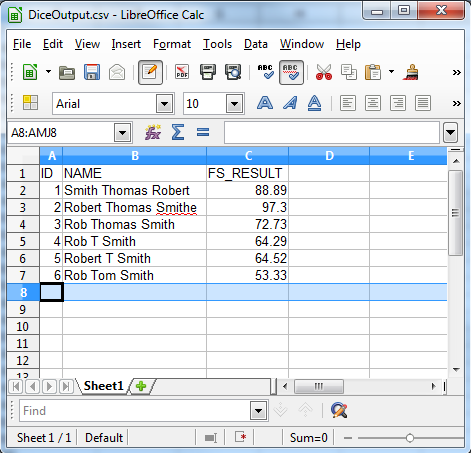
As the output shows the dice coefficient algorithm is useful for finding inconsistent data such as:
- Sequence errors
- Involuntary corrections
- Nicknames
- Initials and nicknames
- Unpredictable use of initials
- Localization
The dice algorithm is faster than the Levenshtein, but can become less accurate when there are many simple errors such as typos.
3. Metaphone and 4. Soundex
the Metaphone and Soundex algorithms compare words or phrases based on their phonetic sounds. Soundex does this by reading through the word or phrase and looking at individual characters, while Metaphone looks at both individual characters and character groups. Then both give codes based on the word’s spelling and pronunciation.
The following SortCL script demonstrates the Soundex and Metasphone search functions:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
In each case, there are three parts that must be used to give us the desired output.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
The line calls the function, and stores the result in the field RESULT. The functions both take two input parameters:
- The field to run the fuzzy search on (NAME in our example)
- The xtring that the input field will be compared to (“John” in our example)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
This line compares the SE_RESULT and MP_RESULT fields, and checks and returns the row if either is greater than 0.
Soundex returns either 100 for a match, or 0 if it is not a match. Metaphone has more specific results, and returns 100 for a strong match, 66 for a normal match, and 33 for a minor match.
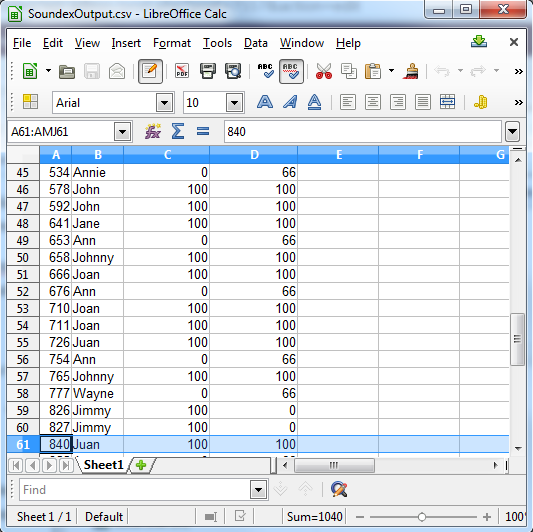
Column C shows the Soundex results. Column D shows the Metaphone results
As the output shows this type of search is useful for finding:
- Phonetic errors
Please submit feedback on this article below, and if you are interested in using these functions please contact your IRI representative. See our next article on using these algorithms in the IRI Workbench data consolidation (quality) wizard.









1 COMMENT
Very nice information. Thanx for sharing this information