 Data Masking/Protection
Data Masking/Protection
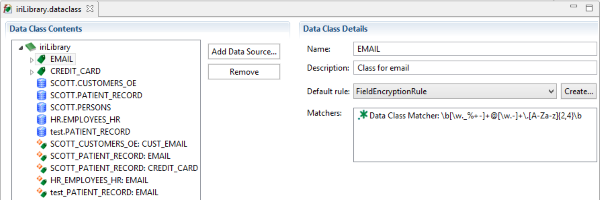
Data Class Database Masking
The Data Class Database Masking Job wizard in IRI Workbench can be used with an IRI FieldShield or Voracity license to mask PII in multiple, disparate database sources that have been previously classified. Read More








