Using the Dark Data Discovery Wizard to Unlock Unstructured…
Editor’s note … this article, first posted in 2014 for the wizard it describes, has been updated as follows:
- June 2015: This wizard was renamed from the Data Restructuring Wizard to the Dark Data Discovery Wizard, and was provided free in IRI Workbench for users of IRI NextForm Lite.
- October 2018: This wizard is now also used with both the IRI CellShield Enterprise Edition (EE) and IRI DarkShield products for searching, extracting, and masking PII in multiple LAN-connected sources at once, and is being enhanced with value lookup, machine-learned NLP models for NER, and fuzzy search criteria. Additional blog content on DarkShield uses will follow.
- April & July 2019: Updated UI images and instructions, updated file formats for DarkShield v2 and v3. IRI Voracity data management platform users can also leverage this wizard for textual ETL applications.
- October 2020: This wizard was subsumed in the IRI DarkShield feature menu in IRI Workbench and renamed to the “New Dark Data Search/Masking Job …” wizard, then described in this article.
- January 2024: The wizard has been updated again for DarkShield V5 to support the upgraded data classification infrastructure and further ergonomic improvements. See this article now.
The idea of dark data in unstructured sources and formats was introduced in Finding Dark Data in Unstructured Sources (to introduce the IRI Data Restructuring Wizard). Recall that corporations and government agencies may have a lot of useful information trapped in these unstructured formats that can be mashed up with other (usually structured) repositories and mined for the benefit of operations, promotions, analytics, law enforcement, etc. However, some of these sources are difficult to parse, and the data they contain need structure to be useful in data integration and reporting contexts. This is where IRI’s Dark Data Discovery Wizard is useful; it unlocks and organizes dark data so it can start driving real value to the business.
The general idea is that, after parsing through the data in unstructured sources, you can output what you’re looking for into a structured text (flat) file, with its layouts automatically defined in a data definition file (.DDF). The file and its metadata repository are easily used and re-used by IRI software to integrate, transform, migrate, mask, and report on that data, and/or feed it to other applications.
Note also that CoSort can query and join over flat files directly, or facilitate the creation and population of tables with DBA-defined primary-foreign keys. In this way, dark data extracts can acquire form and relationships (structure) that can make it a lot more useful.
Using the Wizard
The IRI Dark Data Discovery wizard will search every supported unstructured document type in every directory below the root network drive you specify. The search for your dark data is based on Data Classes, which can contain any combination of regular expression patterns, lookup set files, Named Entity Recognition (NER) models, path filters for semi-structured files, area bounding boxes, and detected or recognized faces.
Here is a list of unstructured sources containing strings that the wizard can search, extract, and structure:
- Free-form text (.txt)
- Microsoft Word documents (.doc and .docx)
- Adobe Portable Document Format (.pdf)
- Extensible Markup Language (.xml)
- E-mail messages (.eml)
- Microsoft Excel spreadsheets (.xls and .xlsx)
- Microsoft PowerPoint presentations (.ppt and .pptx)
- Microsoft Exchange and Outlook (.osd, and .pst)
- Rich Text Format (.rtf)
- Hypertext Markup Language files (.html)
- JavaScript Object Notation files (.json)
- MongoDB and Cassandra NoSQL DB collections
- Various image formats (.tiff, .jpeg, .png, .gif, .jp2, .jpx, .bmp)
To open the wizard, select the DarkShield Menu and select the New Dark Data Discovery Job.

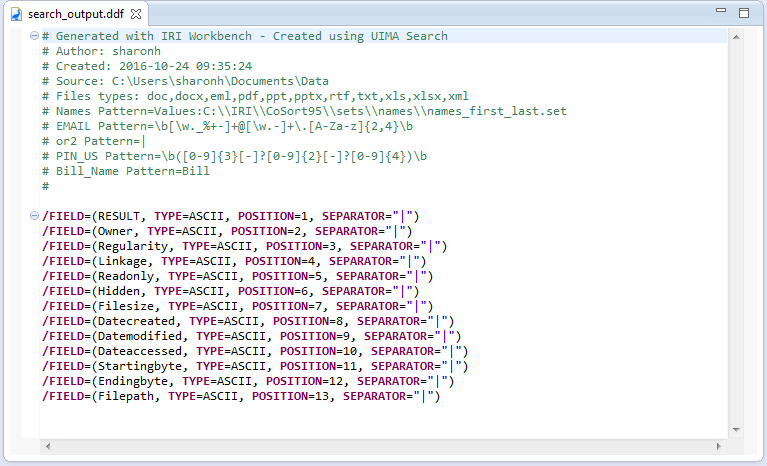
From the setup page, specify the folder and file names for the structured output file and the data definition file (DDF) metadata for that file. The field names in the DDF will correspond to the keywords and patterns you searched, as well as the forensic attributes that you selected to be part of the output file.

Select any combination of sources, which currently support File System directories and SMB shares, along with the list of file types which should be searched.

You can also profile several different forensic aspects of the dark data you’re discovering. The wizard can identify and display the creation, modification, and access dates of the data source, as well as its full path, owner, linkage, and hidden attributes. Choose the delimiter character to offset the fields in the flat results file, such as a comma, or “|” as shown.
There are a few ways to define the values to find:
- Enter a specific value.
- Use regular expressions to search for specific patterns. If you are not familiar with regular expressions, a lot of assistance is available on the internet, including here at Wikipedia. IRI also provides examples in the wizard’s easy-to-use context help.
- Providing an IRI Set file for a dictionary search. A dictionary search is similar to searching for a specific value, except that instead of using one value to search against, you use a file containing many values.
- Include a NER model which was trained to recognize named entities in the context of the sentences
The last two ways are provided through the Data Classes, which can be created and viewed in the IRI Preferences within the Workbench.
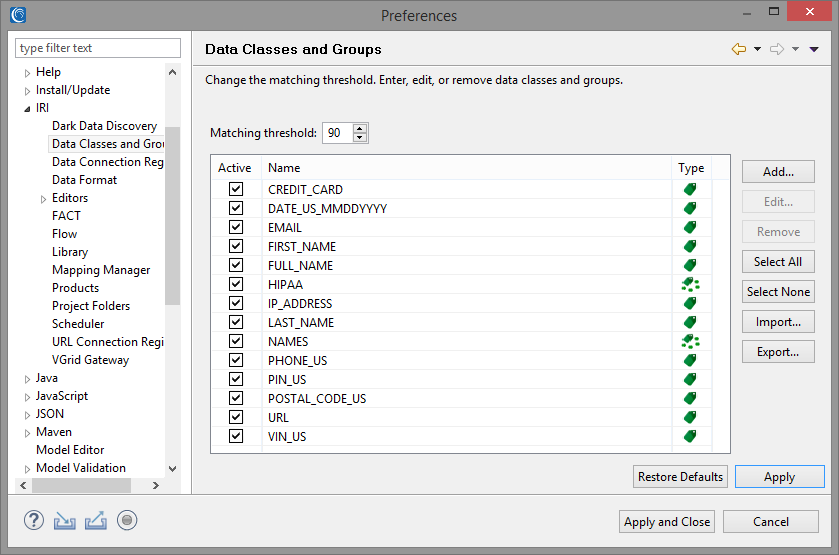
You can associate multiple Data Classes and patterns with a Data Rule by creating Search Matchers. Data Rules will only be applied through the use of IRI DarkShield’s remediation capabilities to obfuscate PII found in unstructured files.

Once you have entered the required information in the wizard, click Finish to generate a .search file containing the configuration parameters that you have selected, and the DDF file describing the layout of the flat file that will be generated by the search.
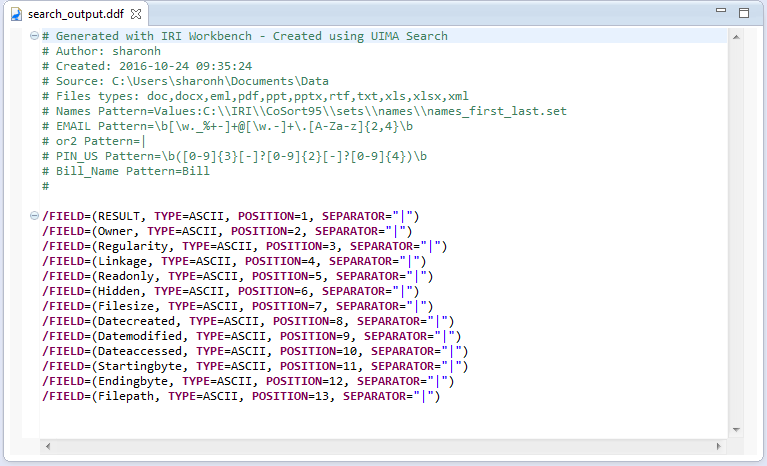
To execute the Search job, right click on the .search file and select IRI > Run Search Job. This will generate the flat file containing the delimited results and metadata information:

So, your now-structured data is stored in a file you can use (repeatedly) for any purpose. And within the same Eclipse IDE, the IRI Workbench, you now have access to this data and its DDF for:
- Data Integration and Transformation
- Data Migration and Replication
- Data Masking (Encryption, De-ID, etc.)
- DB Load and Query Optimization
- Reporting or Hand-offs to BI Tools
- Population of CRM, DB, ETL, and External Apps
See how to use the newly structured output file and its DDF in the next article, Using CoSort on Restructured Data in the IRI Workbench.











1 COMMENT
Very informative post with screenshots describing how it works. Destroying the dark data might be too risky, but analyzing it can be costly. This seems like an inexpensive way to structure the dark data and store it in form of files and fields that can also feed DB tables and analytic/BI tools. I also like that the GUI allows easy selection of both the data formats and metadata we’d want during the extract process so there is granular control over both at once.