Data Class Validation in IRI Workbench
This is the first of a two-part blog series detailing data class validation in IRI Workbench. This article provides an overview of our provided validation scripts and how to use them in a data discovery or classification job. The second article shows how to create a validation script for a custom data class or group.
Beyond their ability to find data across disparate sources that match patterns, IRI Workbench users now have access to a large number of validation scripts — and the ability to create their own — for use in data classification and discovery. The ‘canned’ scripts have been added to all applicable preloaded data classes and common library of Regular Expression patterns.
Why does this extra validation matter? Computational verification of values ensure the data is clean, correct and fit-for-purpose. First class analytics can only happen with quality data. And, in data security governance and privacy law compliance contexts, it is necessary for finding values that contain personally identifiable information (PII) and weeding out otherwise false positives.
For these reasons, the provided scripts and customization facilities for validating data class search results are key value-adds for users of the IRI FieldShield, DarkShield, or CellShield EE tools in the IRI Data Protector Suite. Ultimately, these validators could be used in almost any data cataloging, masking, transformation or reporting job supported in the IRI Voracity platform.
What do these validation scripts check?
Prior to the addition of these scripts, IRI Workbench preloaded data classes only matched data against a specified pattern (though also enabled enhancement through fuzzy and lookup value . matches and/or NER models). Patterns have in fact sufficed in the majority of cases since the structure of the data often had no mathematical logic behind it.
However, data classes such as credit card numbers and national identification numbers require additional validation to ensure the integrity of the data. Common validation checks include:
- Checksum – A checksum is designed to detect errors during transmission and storage of the data. It is calculated by running the data through a mathematical algorithm and often appended to the end of a string of data.
- D.O.B. – Data might have a person’s date of birth encoded within the number itself. A simple check to verify the date is often needed.
- Other – National Identification numbers (NID) often have regional information encoded within the number. Various tests have already been provided to ensure a NID is correct.
Viewing Provided Data Classes and Validation Scripts
The IRI Workbench validation scripts can be viewed through the IRI preferences screen. To open preferences, select the IRI Menu dropdown and select IRI Preferences. Then select the dropdown for IRI (within the preferences window) and select Data Classes and Groups.
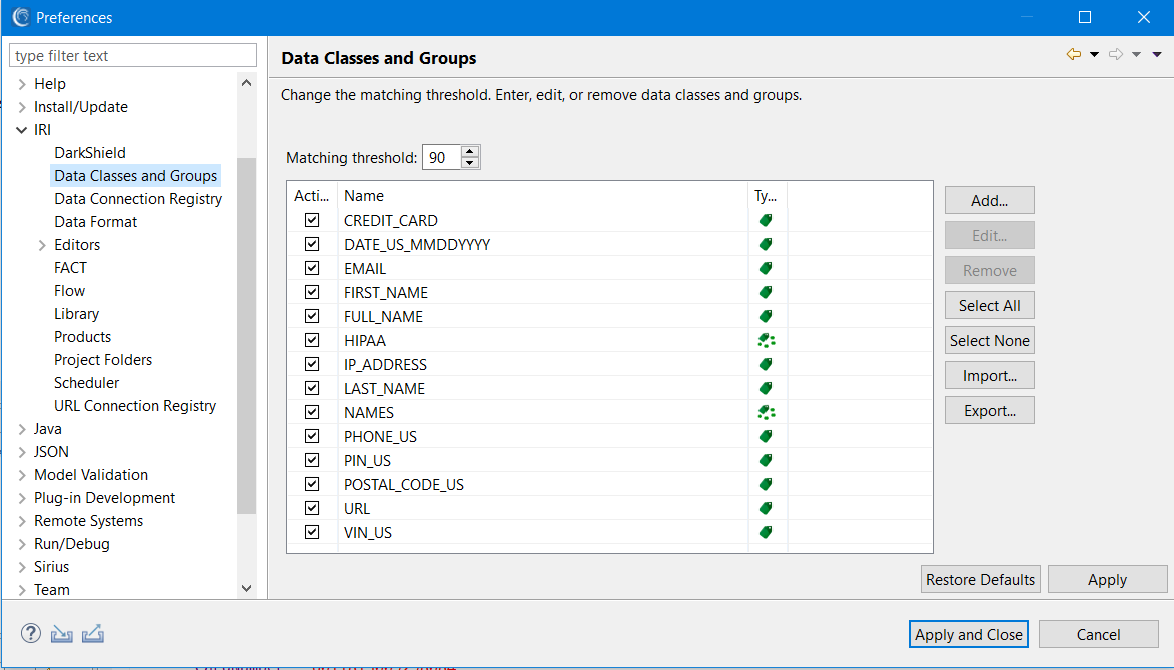
To reset the originally provided data classes if any changes were made, click Restore Defaults. To check if a data class has a provided script, you can select a data class and select Edit. This will bring up the Data Class or Group Edit window. I will use the CREDIT_CARD data class for this example.

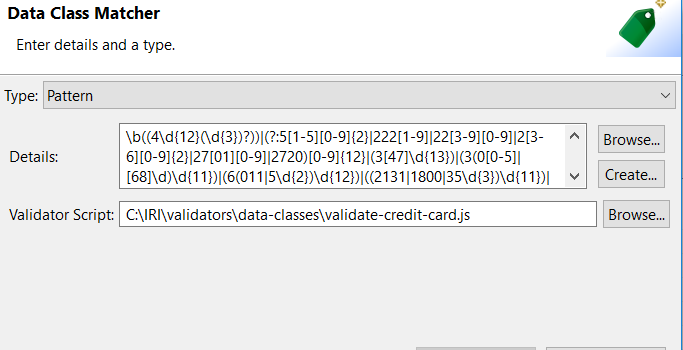
By selecting the associated matcher field and selecting Edit, a Data Class Matcher window will be displayed.

This window details the specific pattern for a class matcher and a validator script path (if one exists). It should be noted that not all provided data classes will have a validator script. For example, the data class FIRST_NAME doesn’t require any validation besides the given pattern.
How do you use these validation scripts?
Using these scripts is easy. They are already added to all applicable preloaded data classes, so it is just a matter of choosing the right data class for the job. We have also added over 45 new data classes supporting various national identification numbers.
For example, users of the IRI Workbench will be able to utilize our preloaded data classes to classify data like:
- Australian Tax File Number (TFN)
- Turkish Public Identification number (T.C Kimlik No)
- China’s Identity Card Number
- Latvian Personal Code (Personas Kods)
- Unique Master Citizen Number
Example: Validation via the Dark Data Discovery Wizard
This example uses some elements of Dark Data Discovery. The general idea is that, after parsing through data in unstructured sources, you can output what you’re looking for in a structured text (flat) file, with its layouts automatically defined in a data definition file (.DDF).
While this example provides a brief introduction to dark data discovery, you may find it useful to read this three part blog series that explores the feature in depth.
For this tutorial, I created a JSON file filled with ten fake credit card entries. Since credit card numbers use a checksum for validation, five of these numbers will have a valid checksum and pattern while the other five will just have a valid pattern.
The goal is to use the Dark Data Discovery wizard to create a search job that will return only the five fully validated credit card numbers.
For reference, this is how the JSON file is formatted:

To access the Dark Data Discovery wizard, select the DarkShield dropdown menu from the IRI Workbench toolbar and select Dark Data Discovery Job. The wizard will open this way:

From the setup page, specify the folder and file names for the structured output file and the data definition file (DDF) metadata for that file.

Select the source URI that contains the JSON file and select Next. The next window will ask you to specify data targets for the remediation (data masking) jobs. Since no remediation is being performed, we can just skip this part by selecting Next again.

From here, you can profile several different forensic aspects — file metadata attributes — of the dark data you’re discovering. The wizard can identify and display the creation, modification, and access dates of the data source, as well as its full path, owner, linkage, and hidden attributes.
For the purposes of this tutorial, you can check every box. The next window will prompt us to add or remove search matchers.

The next window prompts us to add or remove search matchers. Select Add.

Since we already have a preloaded CREDIT_CARD data class, you can just select Browse and point it to the associated class. For the Rule Name field of the CreditCardMatcher, we can create a rule to use with our matcher.
Select Create and create a redaction rule using the default values. Once you have finished creating the matcher, you can click finish to generate a .search file.
Completing the Dark Data Discovery Job wizard generates a new .search configuration file. That file will contain the options we selected, including the source and target of our data, and the Search Matches used to tag PII for discovery, delivery, deletion, and/or de-identification.
To begin the search, right click on the .search file, select Run As, and choose the IRI Search Job.
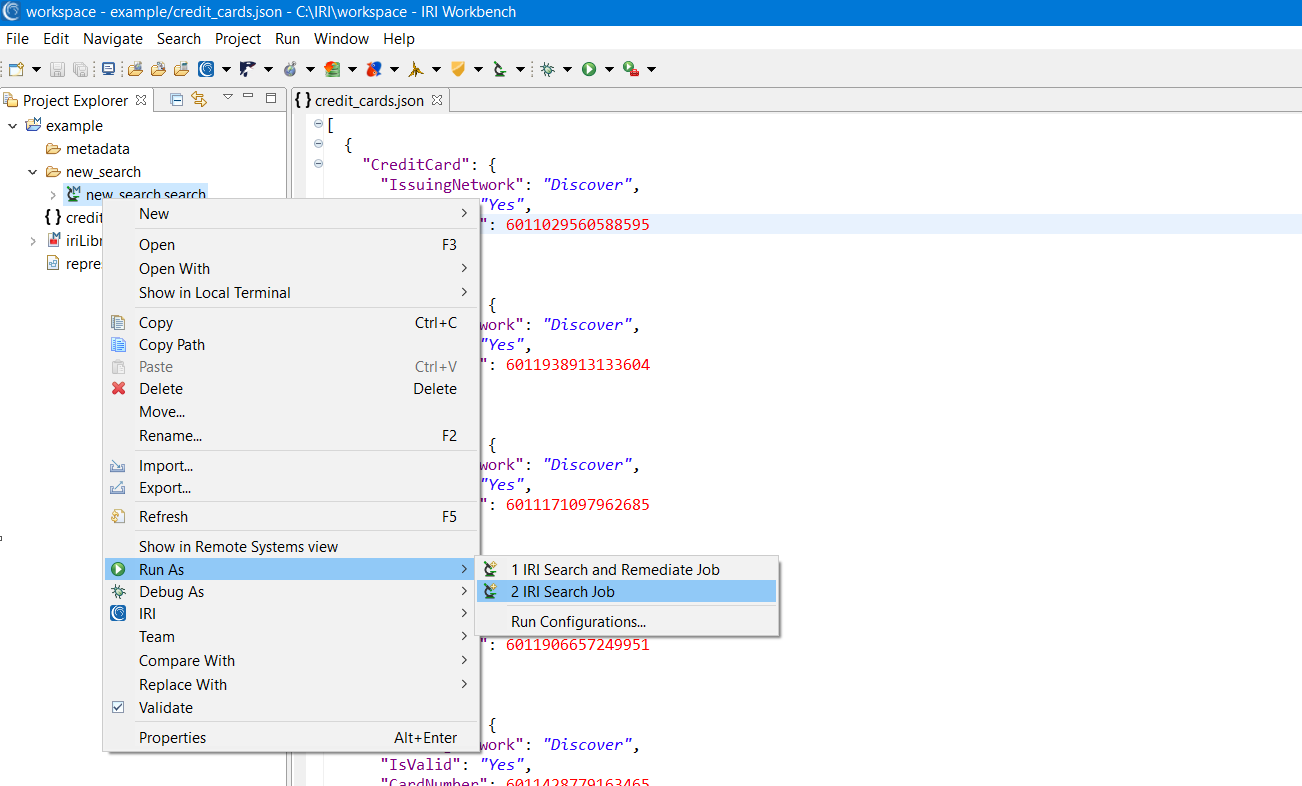
Selecting Search Job will only conduct a search, while Search and Remediate Job will also attempt to mask (or delete) any identified data. Both will generate a .darkdata file identifying any data of interest.
It should be noted that, when handling actually sensitive information, users should ensure that the .darkdata file is not exposed and is safely archived or deleted after the completion of the remediation to prevent PII leakage. IRI is adding a quarantine option for storing the .darkdata file and corresponding search artifacts in a safe location; contact darkshield@iri.com for details.
From the generated new_search.txt file, we can see that the search only returned the credit card numbers that fully passed validation.










1 COMMENT
[…] of a two-part blog series detailing data class validation in IRI Workbench. The first article, here, provided an overview of the validation scripts and how to use them in a data discovery or […]