
Say Hello to UTF-8 Support in CoSort
Thanks to the Internet, the IT world is now a smaller place, too. Information conveyed in different languages must be accurately represented in multiple data sources, email clients, and applications.
In the past, unaccented English letters were represented by ASCII characters in the decimal range 000-127. Then when other groups and countries needed to represent characters that could not be designated by those below 128, their characters were assigned into the decimal range 128-255. The problem was that each new group had designations for their own characters within the same new range. To address the conflict, different ways of representing characters in the same range became known as code pages. The user had to designate which code page to use on his computer. Greek and Turkish characters are defined in different code pages; therefore, they could not be represented at the same time. Representing complex characters used in Asia was even more problematic.
A new system was needed in which any character could be uniquely represented. Eventually a set of unifying encoding systems, or ‘Unicode’, was invented to achieve this. Unicode is a standard for the computer industry that defines the handling and encoding of text for most of the world’s writing systems. The most basic, UTF-8, stands for Unicode Transformation Format 8-bit. UTF-8 is a variable-width encoding system that represents every character in the Unicode character set. Each Unicode character can be represented by one to four 8-bit bytes. Each byte is known as a code point.
Encodings that represent the ASCII characters 0x00 to 0x7f (decimal 000-127) are exactly the same in UTF-8. When a character is a multi-byte character, the first byte is one of the permitted start bytes, and is followed by continuation bytes. The start byte that is used also indicates the length in bytes of the multi-byte character. The ASCII encodings cannot be used for start bytes or continuation bytes in multi-byte encodings. It is because of this system that every character can be uniquely represented and self-synchronizing. When an encoding is corrupted, it is easy to resynchronize, since the beginning of the next character boundary can always be located.
The SortCL program in IRI CoSort — along with spin-off tools like NextForm for data migration and FieldShield for data masking — will process UTF-8 data. Fields in UTF-8 data sources can be re-mapped to different output formats while sorting in encoding order. Consider the following SortCL job script example:
/INFILE=GoodDayDelim.utf8
/FIELD=(phrase,POSITION=1, SEPARATOR='|', TYPE=UTF8)
/FIELD=(language,POSITION=2, SEPARATOR='|' TYPE=UTF8)
/SORT
/KEY=phrase
/OUTFILE=GoodDayDelim.out
/FIELD=(phrase,POSITION=1, CHARS=25, TYPE=UTF8)
/FIELD=(language,POSITION=27, CHARS=19, TYPE=UTF8)]
The input file (GoodDayDelim.utf8) has two pipe-delimited fields for each record. The two fields have each been given the data type of UTF-8. The field phrase has the equivalent of the English “Good Day” in several languages. The field language gives the actual language in ASCII English for the phrase field in that record. The records are sorted in the encoding order for the field phrase and then written to the output file (GoodDayDelim.out). The fields are mapped to fixed positions in the output.
In a record that has only ASCII characters, SortCL would use a “SIZE=number of bytes” to indicate the byte size for each field. Because the fields have a data type of UTF-8 and characters can have more than one byte per character, the size of the field is indicated by using “CHARS=number of characters” per field, where each character can be defined by more than one byte.
So if you have the following delimited input files:
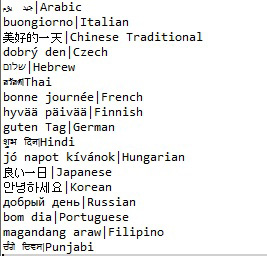
You will get this output file:
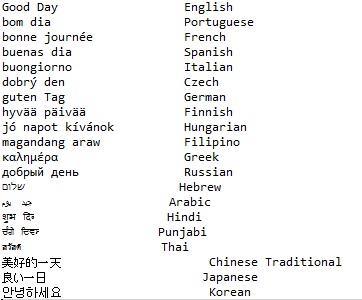
You should notice that the writing for each of the languages is displayed at the same time. This was previously impossible because they would each need to have different code pages active for the display to happen. UTF-8 is becoming the standard for the Internet, and almost all email messages are now transmitted in UTF-8 format.










