
Just How Fast is ODBC? A “Loaded” Comparison.
The Opening Question
ODBC gets a bad rap for speed sometimes … but should it? You’d think from what’s posted online that ODBC is intrinsically slow:
Microsoft disagrees in the case of SQL Server. In Using ODBC with Microsoft SQL Server, Amrish Kumar and Alan Brewer say ODBC is as good as native:
One of the persistent rumors about ODBC is that it is inherently slower than a native DBMS API. This reasoning is based on the assumption that ODBC drivers must be implemented as an extra layer over a native DBMS API, translating the ODBC statements coming from the application into the native DBMS API functions and SQL syntax. This translation effort adds extra processing compared with having the application call directly to the native API. This assumption is true for some ODBC drivers implemented over a native DBMS API, but the Microsoft SQL Server ODBC driver is not implemented this way. … Microsoft’s testing has shown that the performance of ODBC-based and DB-Library–based SQL Server applications is roughly equal.
According to Oracle, their ODBC driver, on average, runs only about 3% slower than native Oracle access. But their ODBC driver may not be yours, and your mileage will vary.
Our users often ask when it’s better to use ODBC or an off-line, flat-file approach to data handling — for which IRI is best known — during very large database (VLDB) operations like:
- ETL (extraction, transformation, and loading)
- offline reorgs
- migration and replication
- data masking
- test data generation/population
Our general answer is that data volume should determine the data movement paradigm. We set out to test that advice with a simple database population (loading) benchmark.
Comparing Two Paradigms
Note that here we are only looking at ODBC vs. bulk, file-based data movement, and not JDBC or other means of distributing data, like Hadoop. We also did not consider other avenues touted to improve data acquisition, like NoSQL, or delivery, like Teradata FastLoad.
ODBC (Open Database Connectivity)
ODBC provides a way for client programs to conveniently access a wide range of databases and data sources that are compatible with ODBC.
ODBC accomplishes DBMS independence by using an ODBC driver as a translation layer between the application and the DBMS. The application uses ODBC functions through an ODBC driver manager with which it is linked, and the driver passes the query or update command to the DBMS.
To populate a table via ODBC in IRI software like the CoSort SortCL program, specify the output process type as ODBC. A sample script targeting columns in a table, rather than a file or procedure, might contain this layout:
/OUTFILE="QA.MILLION_TEST_NEW_ROW;DSN=OracleTwisterQA"
/PROCESS=ODBC
/ALIAS=QA_MILLION_TEST_NEW_ROW
/FIELD=(ACCTNUM, POSITION=1, SEPARATOR="|", TYPE=ASCII)
/FIELD=(DEPTNO, POSITION=2, SEPARATOR="|", TYPE=ASCII)
/FIELD=(QUANTITY, POSITION=3, SEPARATOR="|", TYPE=NUMERIC)
/FIELD=(TRANSTYPE, POSITION=4, SEPARATOR="|", TYPE=ASCII)
/FIELD=(TRANSDATE, POSITION=5, SEPARATOR="|", TYPE=ISODATE)
/FIELD=(NAME, POSITION=6, SEPARATOR="|", TYPE=ASCII)
/FIELD=(STREETADDRESS, POSITION=7, SEPARATOR="|", TYPE=ASCII)
/FIELD=(STATE, POSITION=8, SEPARATOR="|", TYPE=ASCII)
/FIELD=(CITY, POSITION=9, SEPARATOR="|", TYPE=ASCII)
The default ODBC population behavior in SortCL within jobs for: IRI CoSort (bulk transforms and pre-load sorting), IRI NextForm (DB migration & replication), IRI FieldShield (DB data masking & encryption), IRI RowGen (DB test data generation), or IRI Voracity (all of the above) is /APPEND, which adds rows to an existing table. Additional options are /CREATE, for truncate and full insert, and /UPDATE for selective insert.
SQL*Loader
SQL*Loader is an Oracle database utility that loads data from an external (flat) file into an existing table on the same system or across a network. SQL*Loader supports various target table formats, and can handle both selective and multiple table loading.
The data can be loaded from any text file and inserted into the database. One can bulk load a table from the shell using the sqlldr (sqlload on some platforms) command. Run it without arguments to get a list of available parameters.
In IRI ETL and reorg scenarios in which the flat-file data is pre-sorted on the longest index key of the target table, the load command syntax is:
C:\IRI\CoSort10>sqlldr scott/tiger control=ODBC_ONEMILLION_TEST.ctl DIRECT=TRUE
where the .ctl loader control file contains:
INFILE 'C:\IRI\CoSort10\workbench\workspace\CM\twofiftym ilfinalcm.out'
APPEND INTO TABLE ODBC_ONEMILLION_TEST
REENABLE
FIELDS TERMINATED BY "|"
(
ACCTNUM NULLIF(ACCTNUM="{NULL}") ,
DEPTNO NULLIF(DEPTNO="{NULL}") ,
QUANTITY NULLIF(QUANTITY="{NULL}") ,
TRANSTYPE NULLIF(TRANSTYPE="{NULL}") ,
TRANSDATE NULLIF(TRANSDATE="{NULL}") ,
NAME NULLIF(NAME="{NULL}") ,
STREETADDRESS NULLIF(STREETADDRESS="{NULL}") ,
STATE NULLIF(STATE="{NULL}") ,
CITY NULLIF(CITY="{NULL}")
The graph below compares the average time it took for Oracle XE 11gR2 on a Windows server to be populated with five different pre-sorted files using both ODBC insertions and SQL*Loader: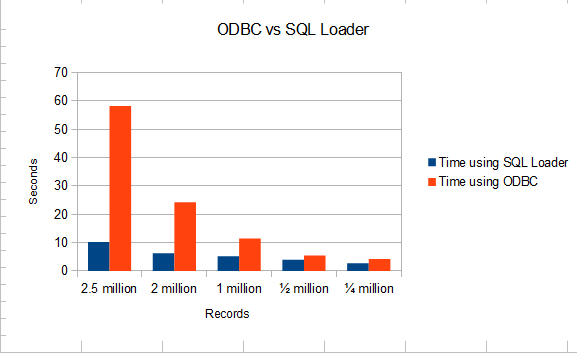
| # of Records | DB Population via SQL*Loader | DB Population via ODBC |
| 2.5 million | 10.25 seconds | 58.25 seconds |
| 2 million | 6.25 seconds | 24.25 seconds |
| 1 million | 5.25 seconds | 11.5 seconds |
| 1/2 million | 4 seconds | 5.5 seconds |
| 1/4 million | 2.75 seconds | 4.25 seconds |
Conclusion for IRI Users
We found that IRI FieldShield users are typically fine with ODBC because it’s more convenient and fast enough for dynamic data masking and static data masking of tables with fewer than a million rows. The same is true for less-than-huge data mapping, federation, or reporting operations in IRI CoSort or IRI NextForm.
For bulk ETL and reorg operations in IRI Voracity, however, what continues to work best are these supported components:
- IRI FACT (Fast Extract) for unloads using native drivers like OCI
- IRI CoSort for big data transformation and pre-load sorting [or IRI RowGen for sorted, referentially correct test data generation]
- Your DB load utility for bulk, direct path loads
So shy of complex and costly paradigms like NoSQL and Hadoop — the trusty flat-file method is still the way to go.










