Data Profiling: Discovering Data Details
Data profiling, or data discovery, refers to the process of obtaining information from, and descriptive statistics about, various sources of data. The purpose of data profiling is to get a better understanding of the content of data, as well as its structure, relationships, and current levels of accuracy and integrity.
Data profiling may reveal errors in, or false conclusions around, metadata (data about data). Finding these problems early on helps improve the quality of source data prior to integrating or storing it in a data warehouse. Understanding the attributes of data in a database table or extracted file, and inspecting data values, helps validate that data content actually matches its metadata definition. Seeing the data and metadata also helps to identify which items are sensitive, or contain personally identifiable information (PII), so that certain columns can be flagged for protective measures. Data profiling thus discovers the characteristics of source data necessary for the identification, use, and lineage of data in integration, security, reporting, and other processes that follow.
Although collected data can oftentimes seem benign or useless, especially when gathered from multiple sources, keep in mind that all data may be useful with the proper application or algorithm. Data profiling is thus also a first step in determining that usefulness (by improving understanding of the data itself).
Since many businesses ultimately rely upon raw data sources for insight into things like product inventories, client demographics, buying habits, and sales projections, a company’s ability to benefit competitively from ever-increasing data volumes can be directly proportional to its capacity to leverage those data assets. Winning/losing customers and succeeding/failing as a business could very well be determined by the specific knowledge an organization’s collected data imparts. Thus identifying the right data, establishing its usefulness at the right level, and determining how to manage anomalies — are essential in the design of data warehousing operations and business intelligence applications.
According to Doug Vucevic and Wayne Yaddow, authors of Testing the Data Warehouse Practicum, “…the purpose of data profiling is both to validate metadata when it is available and to discover metadata when it is not. The result of the analysis is used both strategically–to determine suitability of the candidate source systems and give the basis for an early go/no-go decision, but tactically, to identify problems for later solution design, and to level sponsors’ expectations.”
Data authorities recommend performing data profiling randomly and repetitively on limited amounts of data, instead of trying to tackle large, complex volumes all at once. That way the discoveries can be determining factors for what should be profiled next. Identifying data rules, restrictions, and prerequisites, ensure the integrity of the metadata on which future profiling is performed. Knowing what is supposed to be in certain data files and what is actually there may not be the same thing. So whenever the quality or characteristics of a new source is unknown, experts suggest data profiling first, before any integration into an existing system.
Steps in the data profiling process include: importing all objects, creating configuration parameters, performing the actual profiling, and analyzing the results; none of which are as easy as they sound! Then based upon the findings, schema and data corrections can be implemented, as well as other fine tuning for subsequent data profiling performance improvement.
IRI Profiling Tools
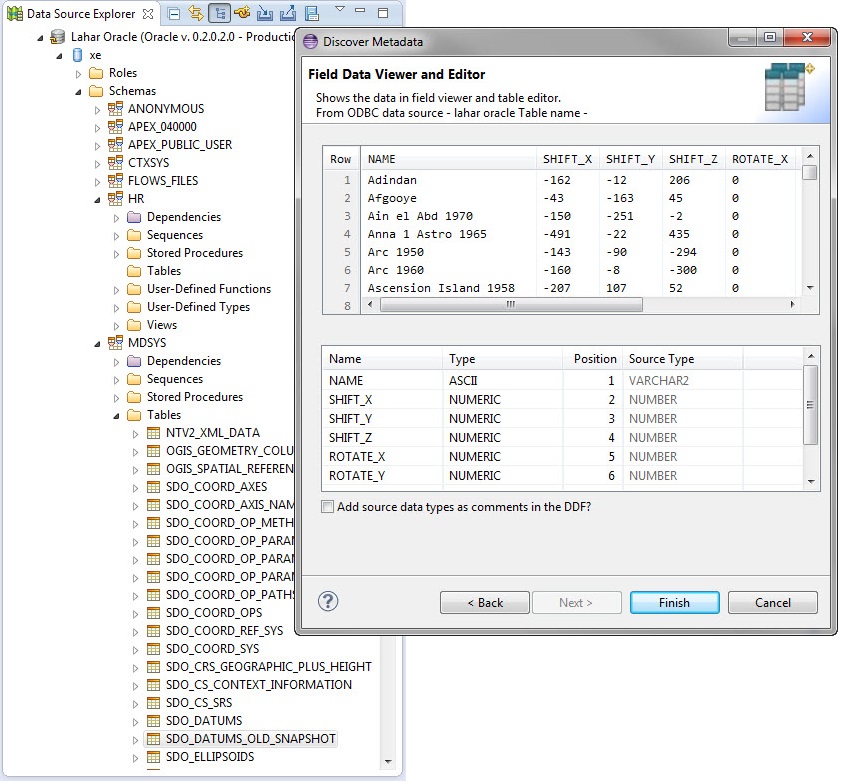
In mid-2015, IRI released a series of free database, structured, and unstructured (dark) data discovery tools in its Eclipse GUI, IRI Workbench. They are summarized at http://www.iri.com/products/workbench/discover-data and link to other articles in this blog which go into more detail.