
When to Use Hadoop
In the last couple of years since this article about the use of IRI CoSort as a parallel data manipulation alternative to Hadoop, IRI released the Voracity platform to process big data in either paradigm. Read More
In the last couple of years since this article about the use of IRI CoSort as a parallel data manipulation alternative to Hadoop, IRI released the Voracity platform to process big data in either paradigm. Read More

Many of the same data manipulation, masking, and test data generation jobs you can run in IRI Voracity® with the default SortCL program can now also run seamlessly in Hadoop™. Read More

Among the many database-centric features in IRI Workbench is the ability to create, modify, and execute SQL statements manually or graphically. These “SQL scrap-booking” features are available through the free Data Tools Platform (DTP) plug-in for Eclipse, which also supports IRI job wizards for database:
profiling, searching, classification, E-R diagramming, and integrity checking integration, including ETL, pivoting, slowly changing dimensions, and change data capture column masking, including format-preserving encryption, redaction, and pseudonymization subsetting, test data generation, and bulk loading migration, replication, and offline reorgsTo use the cross-platform(!) Read More

Sonra recently demonstrated the processing of complex XML data in the IRI Voracity data management platform with the help of Sonra’s Flexter Data Liberator software. Flexter and Voracity are a match made in heaven. Read More

Talend has been on the market for a few years now, and its flexible UI components make it a very reasonable choice for developers when it comes to customization. Read More
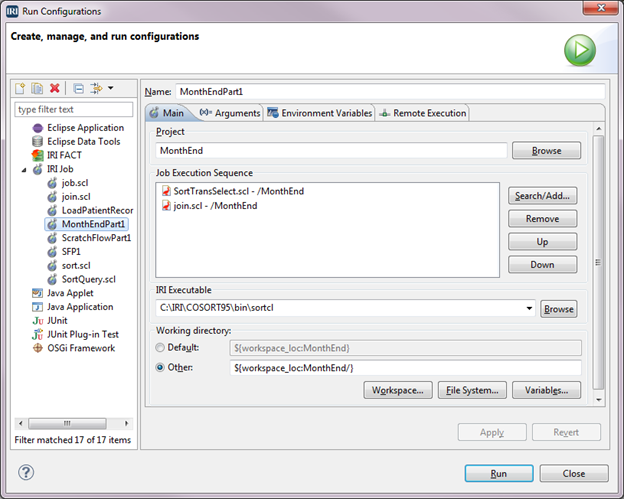
IRI Workbench not only has several ways to create jobs, but also several ways to execute them.
This article focuses on IRI Workbench execution options for scripts based on the SortCL program language, which covers IRI Voracity ETL, CDC, SDC, pivoting and subsetting jobs, as well as its constituent product jobs; i.e., Read More

For the last 30 or so years, the precursor to most large scale business intelligence (BI) environments has been the Enterprise Data Warehouse (EDW). A data warehouse (DW) is usually a central database (DB) for reporting, planning, and analyzing summarized, subject-matter data integrated from disparate, historical transaction sources. Read More

This is the third in a series of articles for creating an IRI Voracity ETL flow of a month-end job for processing sales transactions.
In the first article, we brought an existing CoSort SortCL job script that processes month-end sales transactions into Voracity and made modifications. Read More

The traditional or enterprise data warehouse (EDW) has been at the center of data’s transformation to business intelligence (BI) for years. An EDW involves a centralized data repository (traditionally, a relational database) from which data marts and reports are built. Read More

This is the second in series of articles illustrating on how to use existing IRI CoSort (SortCL) jobs in graphical IRI Voracity ETL workflows, or more simply, flows. Read More

Update Q3’2019: Subsequent to the development of the IRI Voracity Add-On for Splunk described below, there is now also a Splunkbase-registered IRI Voracity App for Splunk available for Seamless Data Preparation, Indexing, and Visualization…
After our first examples of external unstructured data preparation and PII data masking for Splunk generated interest in these capabilities, IRI wanted to develop a direct integration from the Splunk user interface (UI). Read More