
Running Voracity Jobs in Hadoop
Many of the same data manipulation, masking, and test data generation jobs you can run in IRI Voracity® with the default SortCL program can now also run seamlessly in Hadoop™. Read More
Many of the same data manipulation, masking, and test data generation jobs you can run in IRI Voracity® with the default SortCL program can now also run seamlessly in Hadoop™. Read More

Among the many database-centric features in IRI Workbench is the ability to create, modify, and execute SQL statements manually or graphically. These “SQL scrap-booking” features are available through the free Data Tools Platform (DTP) plug-in for Eclipse, which also supports IRI job wizards for database:
profiling, searching, classification, E-R diagramming, and integrity checking integration, including ETL, pivoting, slowly changing dimensions, and change data capture column masking, including format-preserving encryption, redaction, and pseudonymization subsetting, test data generation, and bulk loading migration, replication, and offline reorgsTo use the cross-platform(!) Read More

“That’s all you need in life, a little place for your stuff. That’s all your house is, a place to keep your stuff. If you didn’t have so much stuff, you wouldn’t need a house. Read More

To analyze data successfully, it must first be prepared successfully. Poor quality data creates poor results. Worse yet is data that takes too long to collect and clean because it is too big or too foreign. Read More

The traditional or enterprise data warehouse (EDW) has been at the center of data’s transformation to business intelligence (BI) for years. An EDW involves a centralized data repository (traditionally, a relational database) from which data marts and reports are built. Read More

Has your organization considered using a data lake? This article explains what a data lake is, and how you can fish its murky depths for value in an architecture optimized for your needs. Read More

Very large legacy IT vendors, or what we’ll call megavendors, provide valuable hardware, software, and services to companies worldwide. Often however, their technical approach, product roadmap, and price point will not be the best fit for your use case. Read More

Update Q3’2019: Subsequent to the development of the IRI Voracity Add-On for Splunk described below, there is now also a Splunkbase-registered IRI Voracity App for Splunk available for Seamless Data Preparation, Indexing, and Visualization…
After our first examples of external unstructured data preparation and PII data masking for Splunk generated interest in these capabilities, IRI wanted to develop a direct integration from the Splunk user interface (UI). Read More
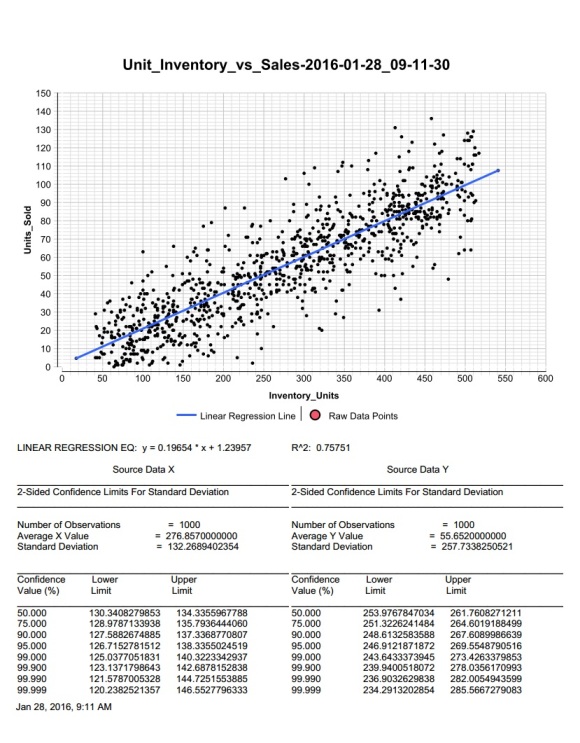
Linear regression is a staple data analysis function for financial, economic, research, and many other disciplines, that helps discover new data correlations. Users of the IRI Voracity platform can now simultaneously process big data from any number of sources and present customized trend lines to help business users make predictions. Read More

