 Big Data
Big Data
Running Voracity Jobs in Hadoop
Many of the same data manipulation, masking, and test data generation jobs you can run in IRI Voracity® with the default SortCL program can now also run seamlessly in Hadoop™. Read More
Big Data
Many of the same data manipulation, masking, and test data generation jobs you can run in IRI Voracity® with the default SortCL program can now also run seamlessly in Hadoop™. Read More
 Business Intelligence (BI)
Business Intelligence (BI)
The “New Reformat Job” wizard in the IRI Workbench NextForm menu virtualizes disparate data sources to produce immediate, fit-for-purpose views. This feature provides a simple and free or low-cost data federation vehicle for IRI NextForm, IRI CoSort, or IRI Voracity platform users. Read More
 Data Migration
Data Migration
The “New Reformat Job” wizard in the IRI Workbench GUI for NextForm converts files to and from a variety of other formats, including fixed and delimited text, CSV, LDIF, XML, COBOL, and more. Read More
 IRI Workbench
IRI Workbench
The Data Connection Registry in IRI Workbench preferences lets you view, add, remove, and modify your database connections in one convenient place. The page displays all your registered connections and specific information about each. Read More
 Big Data
Big Data
This is the final article in a three-part blog series introducing IRI’s new data structuring technology. The first blog introduces “dark data” and the unstructured sources the wizard can analyze. Read More
 Big Data
Big Data
This is the first of a three-part blog series introducing IRI’s new data structuring technology. This article defines “dark data” and the unstructured sources IRI now supports. Read More
 Data Masking/Protection
Data Masking/Protection
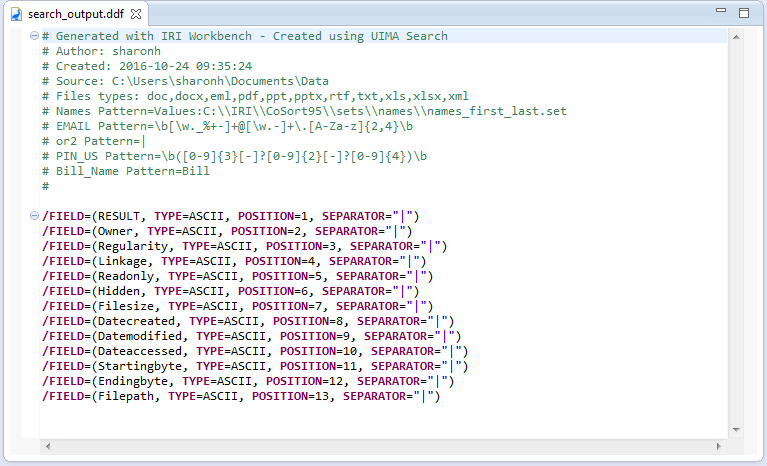
The increasing sophistication of software applications and the expanding role of database testers require high volumes of high quality, realistic test data that can faithfully represent existing, and stress-test new, platforms. Read More
 Big Data
Big Data
One of the best ways to speed up big data processing operations is to not process so much data in the first place; i.e. to eliminate unnecessary data ahead of time. Read More
{kind=link}