Direct Data Masking for MongoDB (2nd Method)
Note: This example demonstrates a more direct method of using IRI FieldShield or IRI Voracity to statically mask PII within structured MongoDB collections. Our older how-to-article on indirect data masking of MongoDB through export/mask/import from 2015 is here, and a newer method through MongoDB’s native driver support in CoSort v10 from 2018 is here.
The latest (fourth method) method which can find and mask PII in both structured and unstructured MongoDB collections using IRI DarkShield in 2019 is here.
In previous articles, we demonstrated file-based examples of masking data in, and generating test data for, MongoDB. Thanks to IRI’s recent success with Progress Software’s DataDirect drivers for MongoDB in the Voracity data management (ETL, etc.) platform and its included components like FieldShield and RowGen, you can manipulate and mask Mongo collection data without intermediate steps.
To expose your collections (tables) in data source explorer views, and ingest their metadata for use in IRI job creation wizards or other Workbench tools, you will need the DataDirect JDBC driver for MongoDB. You will also need the ODBC driver to move data between MongoDB collections in IRI software engines like FieldShield. Although this article shows the use of DataDirect (Progress) drivers, IRI has subsequently partnered with CData which provides both drivers.
This example uses a CUSTOMERS collection as a source and masks the PHONE field using IRI FieldShield, while using ODBC to load the protected results into another MongoDB collection called CUSTOMERS_MASK.
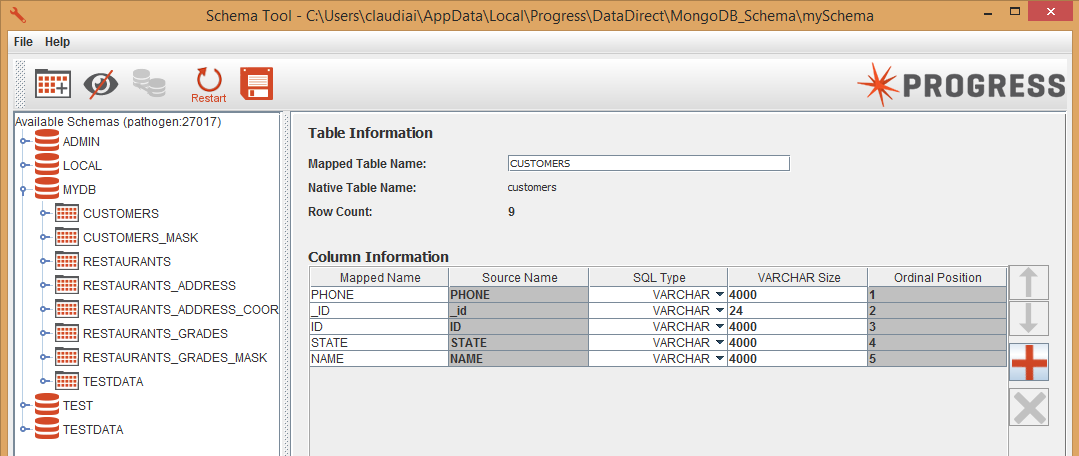
After following the installation instructions for both drivers, you must use the DataDirect Schema Tool (supplied in each driver download) to tell the driver how to map your NoSQL data model to a relational model that IRI Workbench can read.
This tool is a graphical wizard that reads your Mongo database and allows you to select the type of structure you want to use: Normalized, Flattened, or Custom. After selecting Normalized, the tool shows the data structure of the database below.
The data connections can now be set up. Add a DSN in the ODBC Admin screen. When prompted, use the schema file created above. In the Advanced tab, unclick the Read Only box.
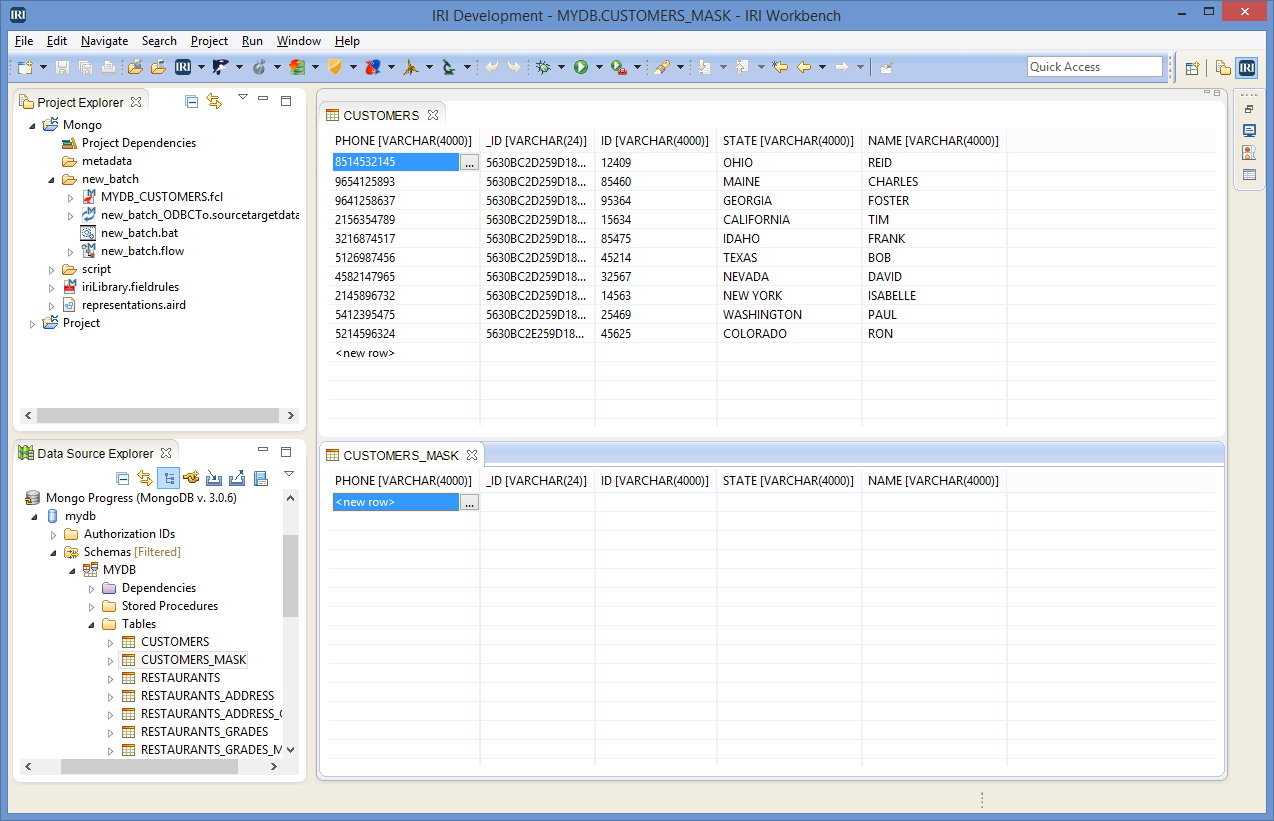
In the IRI Workbench, add a JDBC data connection in the Data Source Explorer. On the Optional properties screen, make sure to add the SchemaDefinition=path\mySchema.config with an absolute path to the schema file created above. Also, add a “ReadOnly=false” property to reverse the driver’s default behavior.
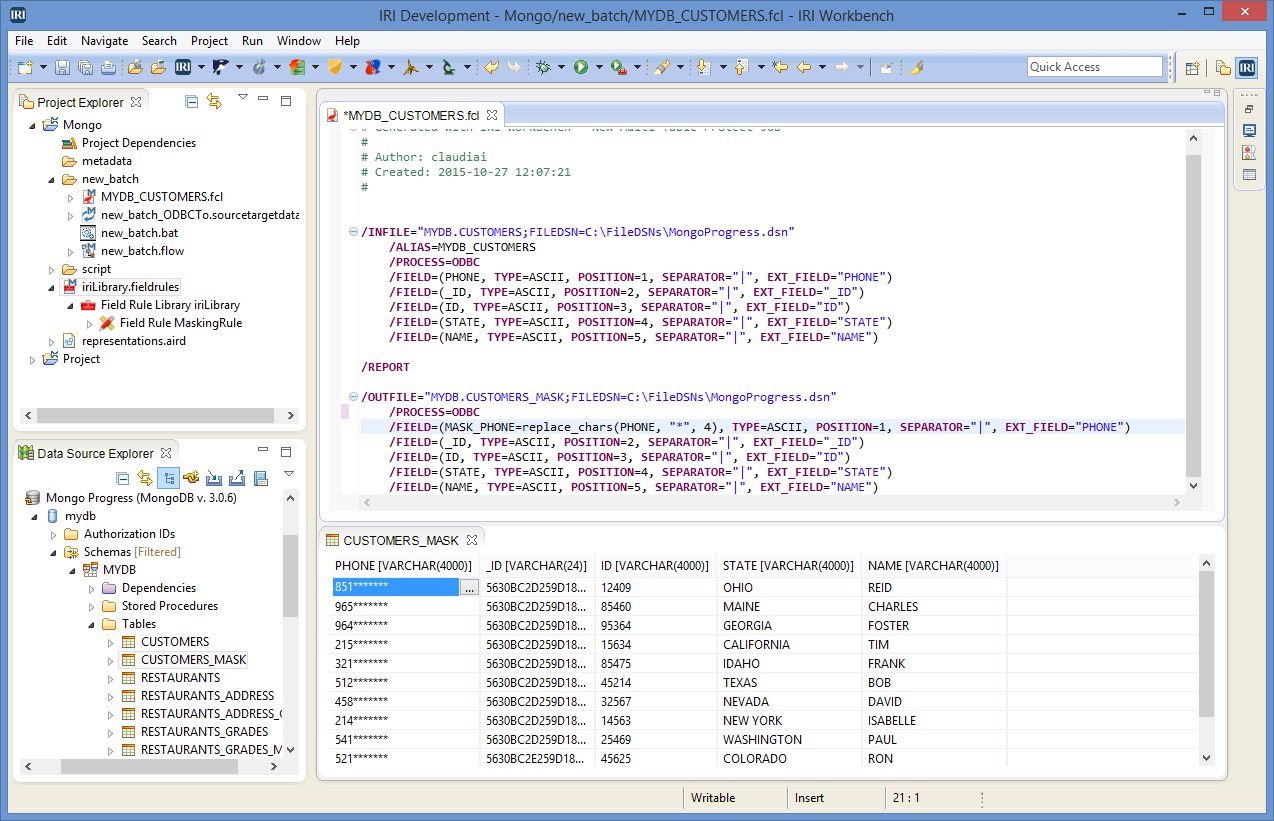
By using the JDBC connector, the data in both tables can been seen. The CUSTOMERS_MASK collection is empty before starting the job, while the PHONE field is unmasked in CUSTOMERS.
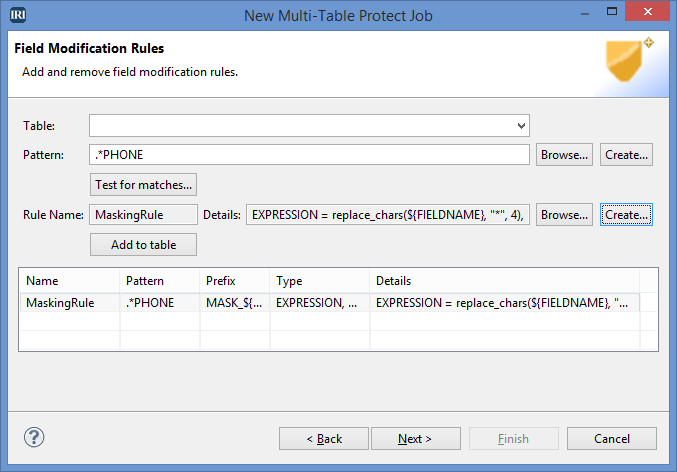
Select the New Multi-Table Protect Job from the FieldShield menu. On the first run, you will be prompted to map your JDBC connection to the ODBC connection. You can also do this in Properties before running the wizard. This example uses ODBC as both extractor and loader to transfer the data.
After selecting the CUSTOMERS collection as the data source and moving on to the Field Modification Rules page, the PHONE column will be masked. This page allows you to use a regular expression to find your desired column and create a new rule or browse for an existing one to apply to that column.
As seen in the “Details” text box, the PHONE field will be masked with “*” character starting at position 4. This will allow the area code of the US phone number to still be visible after masking.
After finishing the wizard, a FieldShield job script, executable batch file, and flow file (usually for use in Voracity ETL project design) are created. Because only one script is created during this job, either the batch file or the script can be executed.
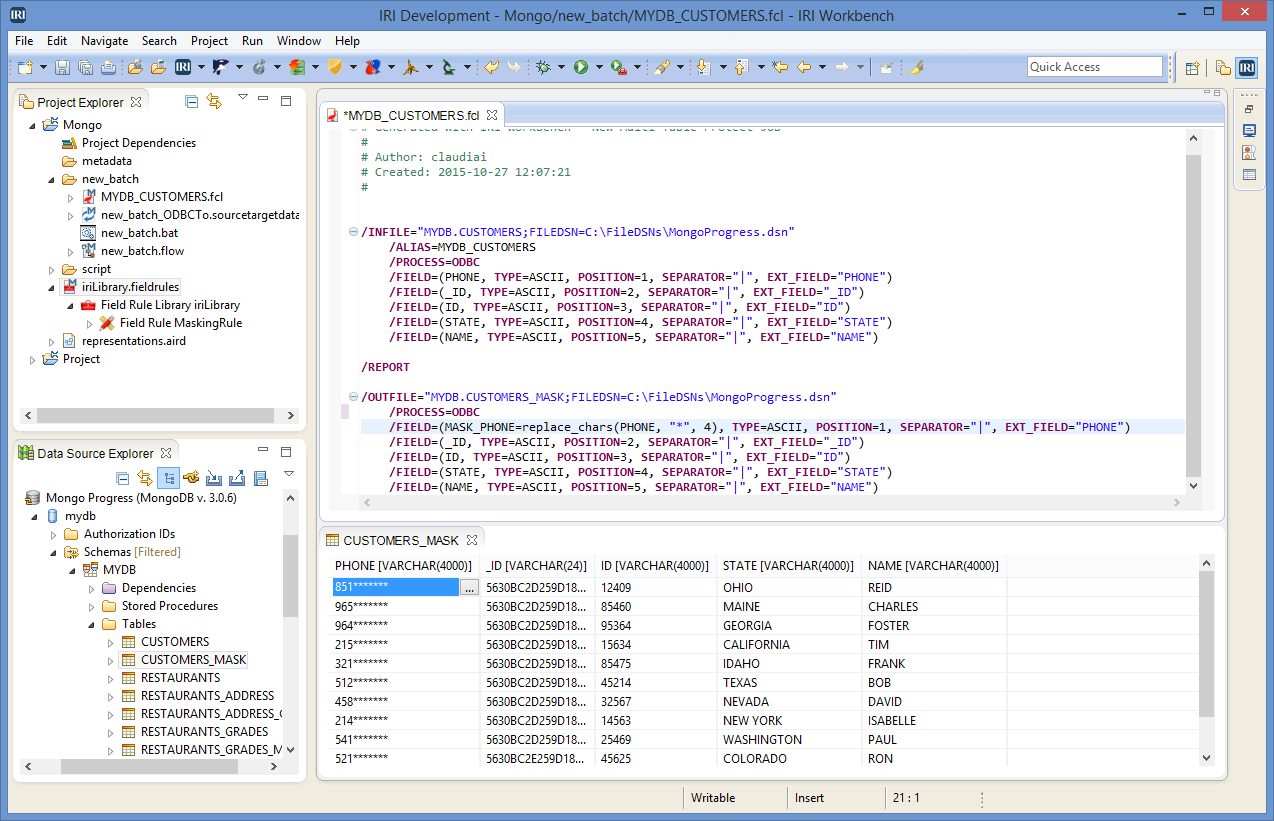
Shown below is the script with the masking function highlighted and a view of the masked data in the CUSTOMERS_MASK collection after execution. Everything was transferred ‘as is’ while the PHONE field was partially masked.
In the next release of Voracity, you will be able to munge, mask, and mine MongoDB data even faster. Native BSON handling (via the CoSort v10 SortCL engine) will dramatically improve throughput in high volume MongoDB environments.









1 COMMENT
[…] The API-level support for MongoDB data is offered in the core SortCL program, which is the default processing engine of the IRI Voracity data management platform, as well as its subset products: CoSort, NextForm, FieldShield, and RowGen. This connection method is the third, and fastest, way that IRI customers can acquire and manipulate data in MongoDB collections. The first is via flat files as described in 2014 here. The second is with ODBC and JDBC drivers described in 2016 here. […]