Masking PII in PDF & Image Files with DarkShield
This article is part of a series of IRI blog articles explaining how to use the IRI DarkShield data masking product for semi- and unstructured data sources. This one focuses on a common use case, the finding and masking sensitive information in .PDF and image files. An important prelude is the previous article on masking documents and files generally using the “New Dark Data Search/Masking Job …” wizard in the IRI Workbench GUI menu for DarkShield. The DarkShield v4 RPC API for files, described here, also supports these and other data sources within a callable web services framework.
As mentioned in previous articles, DarkShield can search for, and mask, personally identifiable information (PII) and other sensitive data in many different file types and documents. Among these are PDF and image files, which are the focus of this article.
As with other document types, DarkShield supports masking in PDFs and images using many off-the-shelf, or custom-integrated, rules. These functions include, but are not limited to, hashing, encryption, pseudonymization, and black-box redaction.
Image files masks are limited to black-box redactions, however. These boxes are placed using either manually defined regions (a/k/a bounding boxes), or Optical Character Recognition (OCR) searches that locate matching text content.
This article provides standalone examples of masking sensitive data in PDF files, image files, and within images embedded in PDFs through the DarkShield wizard in IRI Workbench. Note that this wizard also supports the searching and masking of all those file formats at once, along with others, in one or more local or mounted repositories.
Original PDF document:

PDF-Related Masking Quirks
There are a few points to consider when trying to mask (edit) data in a PDF. The file type is specially crafted to contain the fonts, character sets, shapes, images, and spacing needed so that it can be viewed on any device regardless of operating system.
In a few ways, PDFs act more like images than traditional documents or text files. With that in mind, there are limitations on what can be changed, and how it is changed. It is up to the user to specify the necessary defaults for handling these edge cases when DarkShield encounters them.
One of these issues is “text overflow”. Because a PDF does not automatically adjust the content of a page to accommodate new text, sometimes the masked (replacement) text is too big to fit in the original area where the unmasked data was. By default, DarkShield removes the original text and draws a black box over that area; however, this behavior can be changed by the user.
Another issue is handling characters outside the character set a given PDF file is using, or is available to DarkShield. If neither DarkShield or the pdf know how to draw out a certain unicode character as a PDF glyph, an encoding error will occur.
Again, the DarkShield default is to remove the original text and replace it with a black box, although the user can opt to leave the original text as is in order to mask it differently in a subsequent masking operation. For example, the user can replace a character with one character for which DarkShield knows the glyph.
How DarkShield handles both cases is explained in the PDF Configuration section below.
Using the Wizard
To search and mask both PDF and image files, among other unstructured files, launch the “New Dark Data Search/Mask Wizard Job …” wizard from DarkShield menu (charcoal shield icon) in the top toolbar of the IRI Workbench IDE, built on Eclipse.
Follow the same steps documented in the previous blog article. The only steps that differ are PDF-related.

On the first page of the wizard, specify the IRI Workbench project folder and name for the search configuration artifacts. This article won’t go into great detail regarding the job setup, please refer to the original article if you are unfamiliar with this wizard.

Next, specify the root folder(s) that contain the files to search and mask:

Select the file types you want involved. In this example, PDF will be the only one selected but other file types can be selected, and their details will not affect the PDF masking process.

Select the target directory to place the masked PDFs. Selecting the same location of the searched PDFs will replace the originals permanently.

Select the metadata that will be shown with the search results:

The next page covers configuration and selection of search matchers. Each search matcher requires a data class and a relevant masking function. See this article on data classification in IRI Workbench if you are not familiar with the concept or how classes are used in global search and mask operations.
In this document example, I will search for names using default methods in the Data Class preferences. They will be masked with Format Preserving Encryption.

PDF Configuration
The last page of the wizard is the PDF Configuration Page. Here you specify how to handle text overflow and encryption errors. Each option is explained in the next section.
As mentioned, DarkShield provides a few options when the masking applied is larger than the original text for the PDF. Available options include: 1) truncating the ciphertext to the same length as the original; 2) black box redaction; 3) leaving the ciphertext as is (potentially causing the text to draw over existing text); and, 4) leaving the original text as is.

On encoding error issues will have an option between black box redaction and leaving the original text as is.
Clicking Finish will close the wizard and create a .search file in the directory specified from the first page of the wizard. Right clicking on the .search file presents the option to execute an IRI DarkShield search job only, or a search and mask job.
Either option will create a .darkdata file containing the search results, but the latter will perform masking as well. The .darkdata file contains a tree view of the files that were searched along with their search results (for more details refer back to the original article):

Again, right clicking on the .darkdata file brings up the IRI option to execute the masking job. Once complete, the masked PDF files will be in the target directory.
Results of Format Preserving encryption:

Text Overflow and Errors
To better show how PDF configuration works, here is the previous document but with Hashing used as the masking function. Each example shows one of the options available from the PDF configuration page.
Black Box Redaction (bounding box that covers original text):

Truncated (shorted masked text to fit the original text length):

Replace as is (full length masking text, may cover any text near the original text):
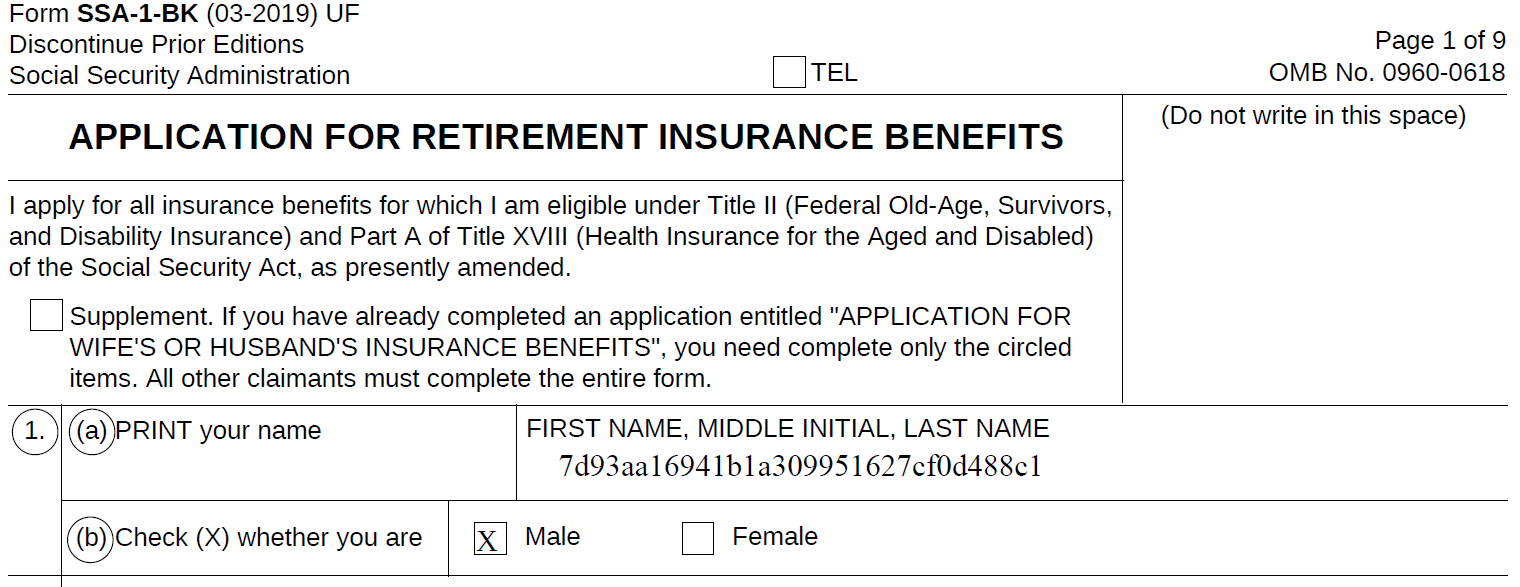
Image Masking
Images can be annotated using the same Data Class matchers that are used for regular text files. DarkShield extracts the text within the image using Optical Character Recognition (OCR) using Tesseract OCR models.
In some cases, however, the text extraction approach can be slow and/or unreliable. DarkShield provides a simpler alternative that can be used in addition to OCR, namely an Image Bounding Box matcher that marks a portion of an image file using a bounding box relative to the size of the image.
Bounding box matching is useful for images that are always in the same format but with different information in predetermined locations. Some examples of this may include drivers licenses, identification documents or cards, Social security cards, or any type of standardized form.
To start, open the Preferences in Workbench and locate the IRI section. Then click on Data Classes and Groups. This presents a list of default data classes and groups included with Workbench, along with those created after installation.

To create the image bounding box, navigate to the Data Classification preference page and click Add to create a new Data Class. This will bring up the New Data Class or Group wizard. Name the Data Class and click add to bring up the Data Class Matcher page.
Next to Type, click the dropdown arrow and select Image Bounding Box:

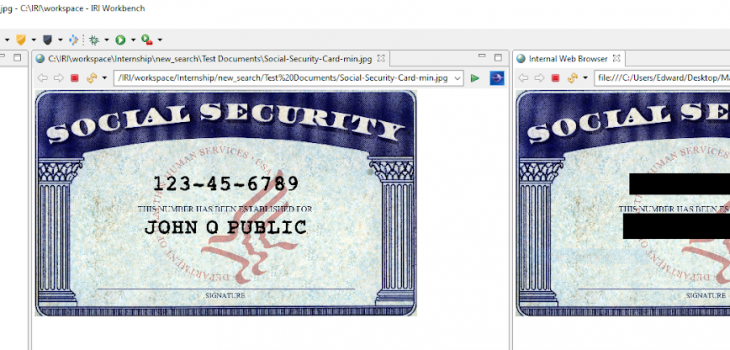
Select Browse to select a reference image on which to locate the bounding box. In this example, my standard image forms are Social Security card photos like this:

Selecting the file will bring up the image in the wizard. You can then left click and drag over the area where sensitive PII is located, in this case the Social Security Number itself:

Only one box can be created at a time (in this case the SSN), so another one (for the name) will have to be created afterwards by adding another Image Bounding Box matcher.

Click ok to finish this bounding box, and then Add to start the next one.

When using these Bounding Box Matchers in search and masking operations, DarkShield will draw a black rectangle over the same regions that you have selected in any image that it encounters. The bounding boxes will be scaled relative to the size of the encountered image, so you do not have to worry about making sure the searched images are the same size as the reference image.
Now a bounding box has been applied to both the SSN and the name on the card. Click OK on this page and on the New Data Class or Group wizard. To finish, Click apply or Apply and Close on the Preferences page.
To start the masking, create a new search and masking job like before, but include the Data Class that was just created plus the image file type(s) and data source(s).
Before DarkShield
After DarkShield

Embedded Images
Not only can DarkShield search and mask image files, but it can also search and mask embedded images within PDF and Word documents. Here is an example of one:
PDF with Embedded Image

To enable this option, click the checkbox for the “Search Embedded Images” option from the PDF Configuration Page:

And that’s it, no further configuration is needed. If DarkShield finds something in an image, it will automatically create a black box around the text it finds just like it will for regular image files.
Here, DarkShield searched the PDFs and its images for names and SSNs, and redacted both:
Embedded Image Masked

Contact your IRI representative if you have any questions or need assistance using DarkShield.