Using DarkShield with Relational Databases
Editor’s Note: The content in this article has been deprecated with the release of IRI DarkShield Version 5 in 2024. To see how you can search and mask data in RDBs with the DarkShield GUI now, see this article. To see how to do it in the API, see this article.
Introduction
In the previous article, we discussed how IRI DarkShield finds sensitive information using Data Class Search Matchers and masks it consistently using Data Rules. We also alluded to DarkShield’s internal processing model, which is based on an abstract view of data as a collection of documents. Understanding this model will help you understand how DarkShield handles structured, semi-structured and unstructured data in relational databases in much the same way it does file-based documents in local file systems, network shares, or S3 buckets.
Note that the functionality described in this article is only supported through the IRI Workbench graphical IDE, built on Eclipse. It cannot be replicated through the DarkShield Command Line Interface (CLI) or Remote Procedure Call (RPC) API frameworks at this time.
DarkShield vs. FieldShield
IRI FieldShield has been the primary product for masking data in flat files and relational databases. There is now overlap due to DarkShield’s new ability to classify, reach, and mask the same data as FieldShield. The main difference between the two is that FieldShield deals with data on a column basis, while DarkShield’s approach to searching and masking is more granular.
Thus in practice, DarkShield can find and mask PII in Large Objects (LOBs), XML, and other free-form text embedded within columns, while FieldShield can only work with First Normal Form (1NF) atomic column data. However, DarkShield jobs can only discover, extract, and mask data, while FieldShield job specifications can be also be used to “mask data on the fly” within IRI Voracity-supported ETL, subsetting, migration, replication, cleansing, and reporting scripts.
Following is a comparison of DB-centric capabilities in DarkShield and FieldShield:

Both products share the same Eclipse front-end (IRI Workbench), executable back-end (SortCL), data classes, and masking functions. That means you can, for example, encrypt in DarkShield and decrypt in FieldShield, for example. The key interface difference is in their job design wizards and serialized configuration files (defining the masking jobs).
Both DarkShield and Fieldshield are also included in the IRI Voracity data management platform (along with CellShield EE and RowGen), should you require both and more capabilities. DarkShield pricing information is on this page.
Tables are Documents, Cells are Embedded Documents
To understand the extent of DarkShield searching and masking capabilities within relational databases, it’s important to remember the DarkShield mantra that “everything is a document.” In the context of relational databases, every table is considered a tabular document, which means it can be filtered by column name or index much like you would a CSV or Excel file.
Moreover, every cell inside of a table is treated as an embedded document, meaning that cells will be parsed according to their detected media type (text, json, pdf, etc.). Embedded PDFs and images in BLOB columns, for example, will be searched and masked as if they were regular files in a file system, but stored inside the table.
To reinforce this mental model, we will show you how DarkShield handles a table containing free form text and XML data. The same logic that we will outline here can be applied to tables which contain BLOB data, like embedded images and PDFs.
Data Connectivity and Setup
If you don’t have any connection profiles to the database(s) that DarkShield needs to access, refer to these example how-tos to add them in IRI Workbench; note that only JDBC connections are needed for DarkShield. The rest of this article assumes that you are familiar with Data Classes and Data Rules from our introductory article, which we encourage you to read before continuing now.
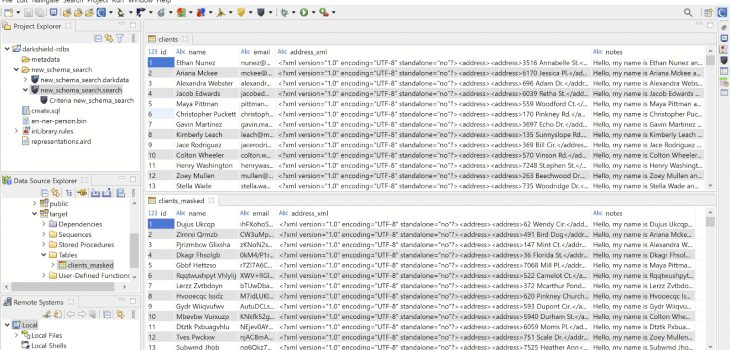
To demonstrate DarkShield RDB search/mask capabilities, I created a simple Postgres table named “clients”, which contains some structured columns (name, email), as well as an XML column for address data (address_xml), and a free-flowing text field (notes).
The DDL for this table can be created and executed in Workbench by clicking ![]() on SQL scrapbook in the
on SQL scrapbook in the ![]() Data Source Explorer view, selecting the connection profile in the Name field (in our case, the connection profile is called DarkShield), and running this DDL statement:
Data Source Explorer view, selecting the connection profile in the Name field (in our case, the connection profile is called DarkShield), and running this DDL statement:
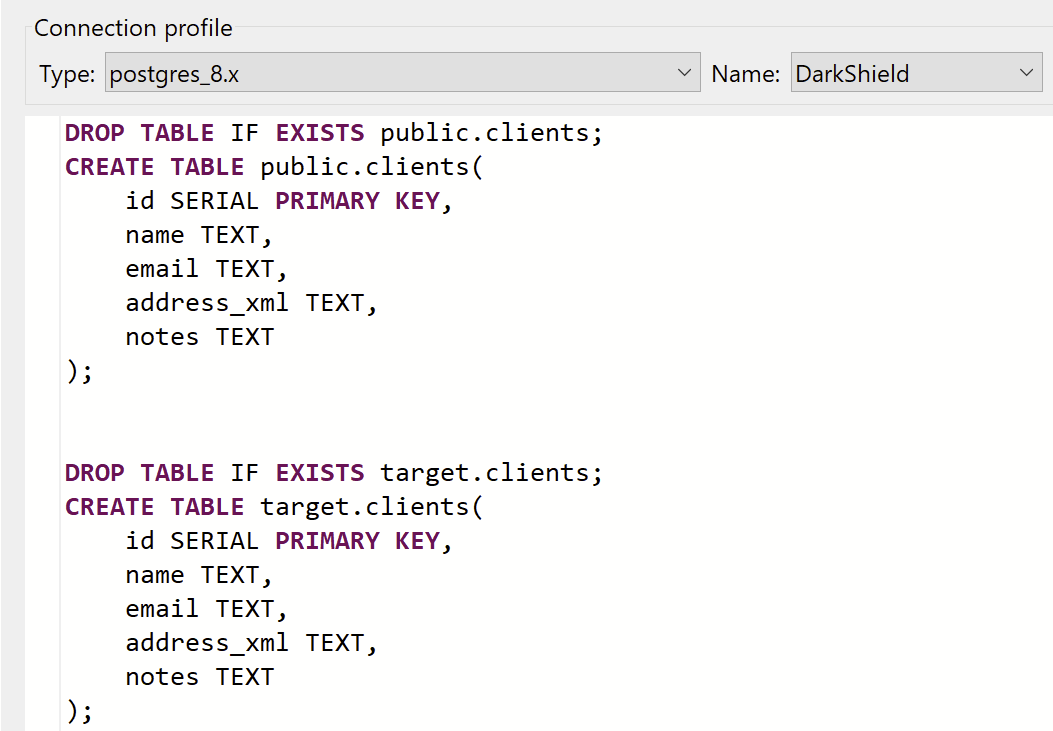
We can right click inside the scrapbook and select Execute All to create two tables, one inside our public schema to act as our source table and another inside the target schema. Note that if the target table doesn’t exist, DarkShield will try to automatically create a target table DDL from the metadata of the source table.
If the DDL fails to execute, DarkShield will log an error in the error view. To see what DDL DarkShield will attempt to generate for your source table, navigate to the table in the Data Source Explorer, right click on the table and select Generate DDL.
Populating this table with test data is outside the scope of this article. Please see IRI RowGen for more information about our product synthesizing structurally and referentially correct RDB test data from scratch. RowGen also runs from IRI Workbench and is included in Voracity.
The Dark Data Schema Masking Wizard
Once your connections are established, you can start defining your search and masking criteria. From the ![]() DarkShield menu dropdown options off the IRI Workbench top toolbar, select the New Dark Data Schema Search/Masking Job option.
DarkShield menu dropdown options off the IRI Workbench top toolbar, select the New Dark Data Schema Search/Masking Job option.
Source Selector
After specifying your Workbench project and job names in the setup page, click Next to begin filling out the Source Selector page. Here, we can select our connection profile or create a new one from scratch, and then select the schema we wish to search for sensitive information:
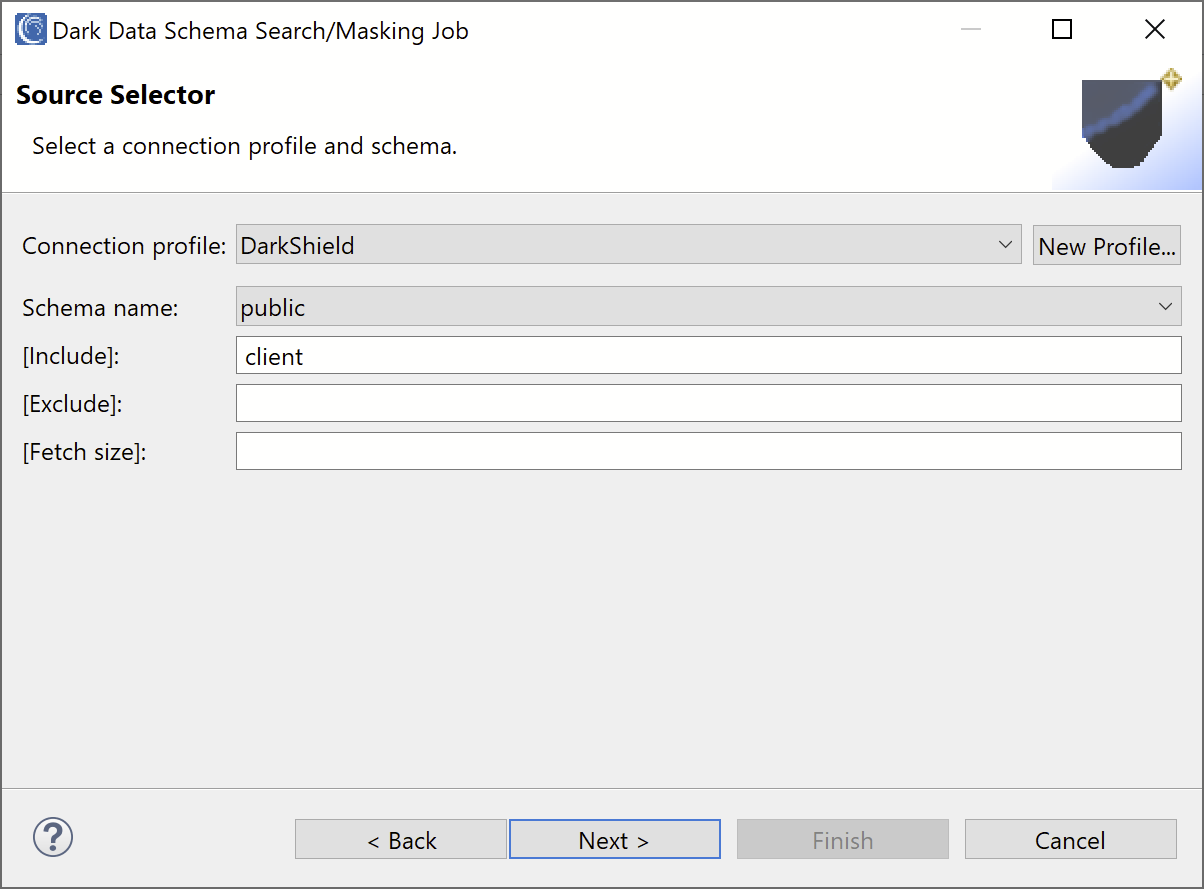
The form also contains several optional fields:
- Include: A regular expression pattern for including tables. In our example, we set the field to “clients”, which is our newly created source table.
- Exclude: Another regular expression pattern for excluding tables. If both an Include and an Exclude pattern is specified, both will be applied to filter the table names.
- Fetch Size: This is an important parameter for defining how many rows are fetched from a table in one network pass. Note that this parameter does not limit the number of rows searched, but instead affects the number of fetches that will need to be performed to read the entire table. You may want to tweak the fetch size depending on the amount of memory on your computer, the size of the returned rows, and the network latency. Note that the JDBC specification classifies this option as a hint, so it’s up to the driver whether this parameter is used.
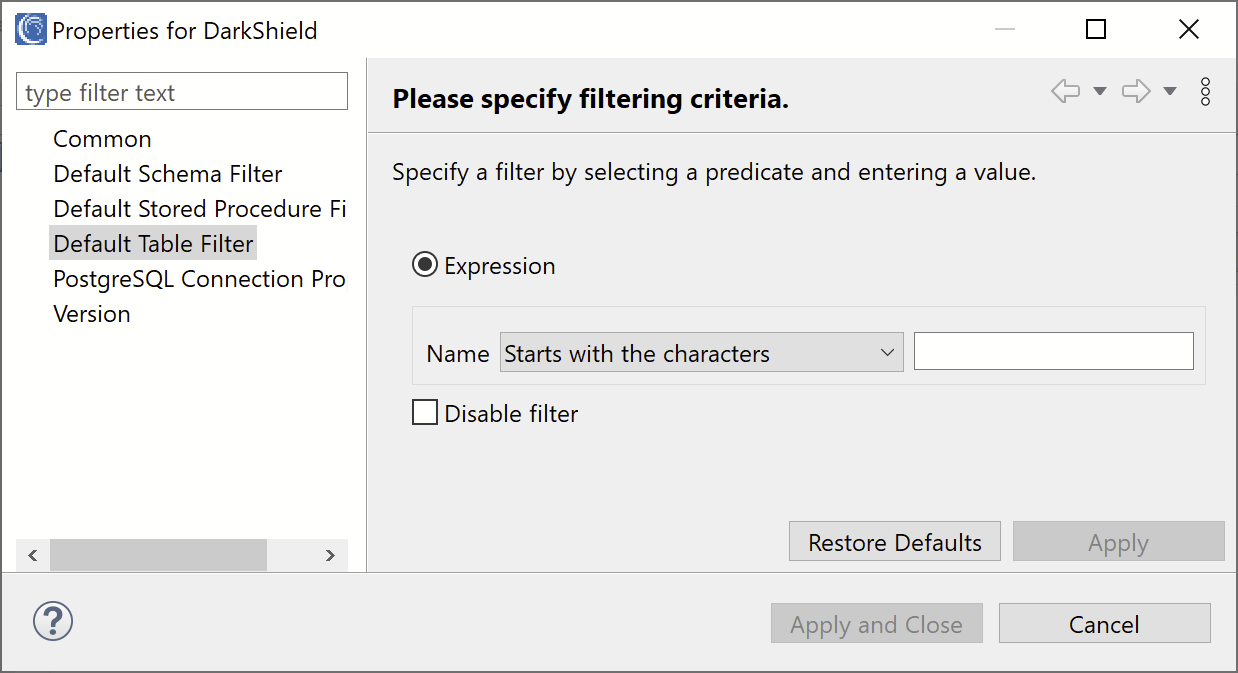
If you are not comfortable using regular expressions for filtering on tables, DarkShield also respects any schema and table filters that were applied directly to the connection profile itself. To create the table/schema filters, right click on the connection profile in the Data Source explorer and select Properties, then select either the Default Schema Filter or the Default Table Filter tab and enter your filter expression:
After finishing the Source Selector page, click Next to continue to the Target Selector page.
Target Selector
On the Target Selector page, we specify the target of all the masked source tables. You can select a different connection profile and/or schema to target different tables, or select the same schema as the source to overwrite the original source tables.
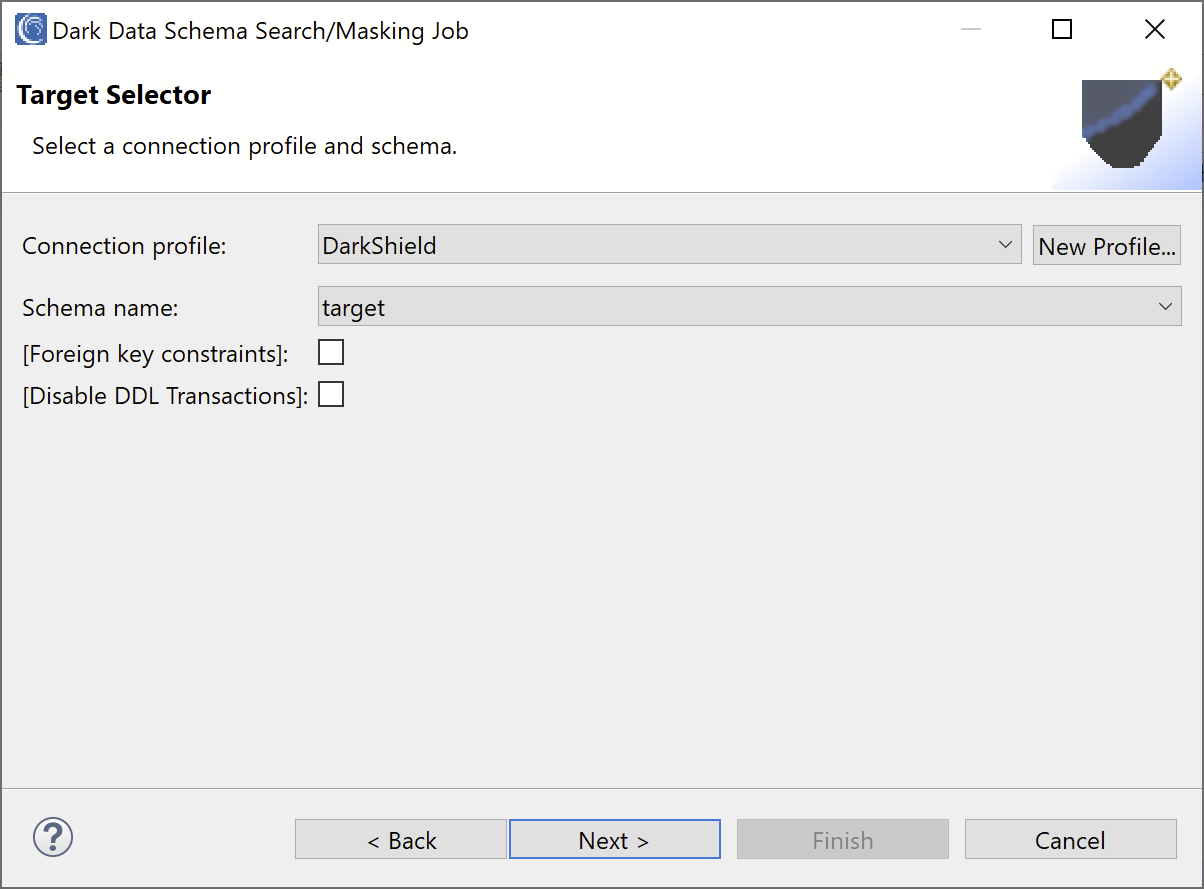
DarkShield uses a set of strategies to determine how the target tables will be populated with masked data depending on the relationship between the source and target schemas:
- If we’re updating the source schema, DarkShield will attempt to find a primary key, unique index, or compound key for each source table in order to create the necessary batched update statements. Tables without any unique keys specified in the metadata cannot be updated by DarkShield, which will log an error.
- If targeting a separate schema and a table with the same name already exists, DarkShield will check the column names to make sure they match between source and target. If they match, the target table will be truncated, otherwise it will be dropped and re-created using the source table metadata. Batched insert statements will be created.
- If the target table does not exist, a new table will be created using the source table metadata. Batched insert statements will be created.
By default, the batch size for the inserts/updates will be equal to the fetch size. This option may become configurable in the future.
All DarkShield DDL and DML operations are executed in a transaction, which means that if a failure occurs, DarkShield will attempt to rollback the changes to prevent saving the masked table in an incomplete state. This is particularly useful when updating source tables to prevent only partial masking of the data.
The form also contains several optional fields:
- Foreign key constraints: select this checkbox if you want to preserve the foreign key constraints in the masked tables when targeting a different schema. This option only affects tables that are created by DarkShield, constraints for existing tables will not be affected. If the filtered source tables contain foreign key references to tables that are not included in the set of source tables that are being searched and masked, they will be copied over without any changes to the target table. Foreign key constraints are enabled after all the masked tables have been created. Any validation errors when attempting to enforce the foreign key constraints will be logged in the error view, but the masked table will remain in place. It will be up to the user to re-enable any foreign key constraints that could not be created manually in those cases.
- Disable DDL transactions: select this option to disable transactions for DDL statements. Certain Databases, like Oracle, do not support executing DROP and TRUNCATE statements inside of a transaction. By default, DarkShield will exit with an error message if it needs to execute a DDL statement within a database that does not support DDL transactions. Use this option with care, since you may risk losing the original data in your target tables if DarkShield fails to perform the masking and is forced to execute a rollback. This option is not relevant for updating the original source tables, since no DDL statements are executed.
Click Next to proceed to the Search Matchers page.
Search Matchers
With the source and target configuration out of the way, we can now focus on defining how data will be found and masked. Let’s start defining new Search Matchers for our data.
NameColumnMatcher
Click Add to open the Search Matcher Details dialog. In the Name field, enter the name “NameColumnMatcher”.
The first Search Matcher we define will deal with the 1NF column for people’s names. If we had a set file containing a list of names, we could search using that, but that’s less efficient and reliable if we know the pattern for the column headers containing names. While FieldShield can classify an entire column as a NAMES column based on either its name or contents, DarkShield can filter on specific column names and then select all the contents within as sensitive data.
In the Data Class Name field, click Create to create and save a new Data Class or Group in the global IRI Preferences.
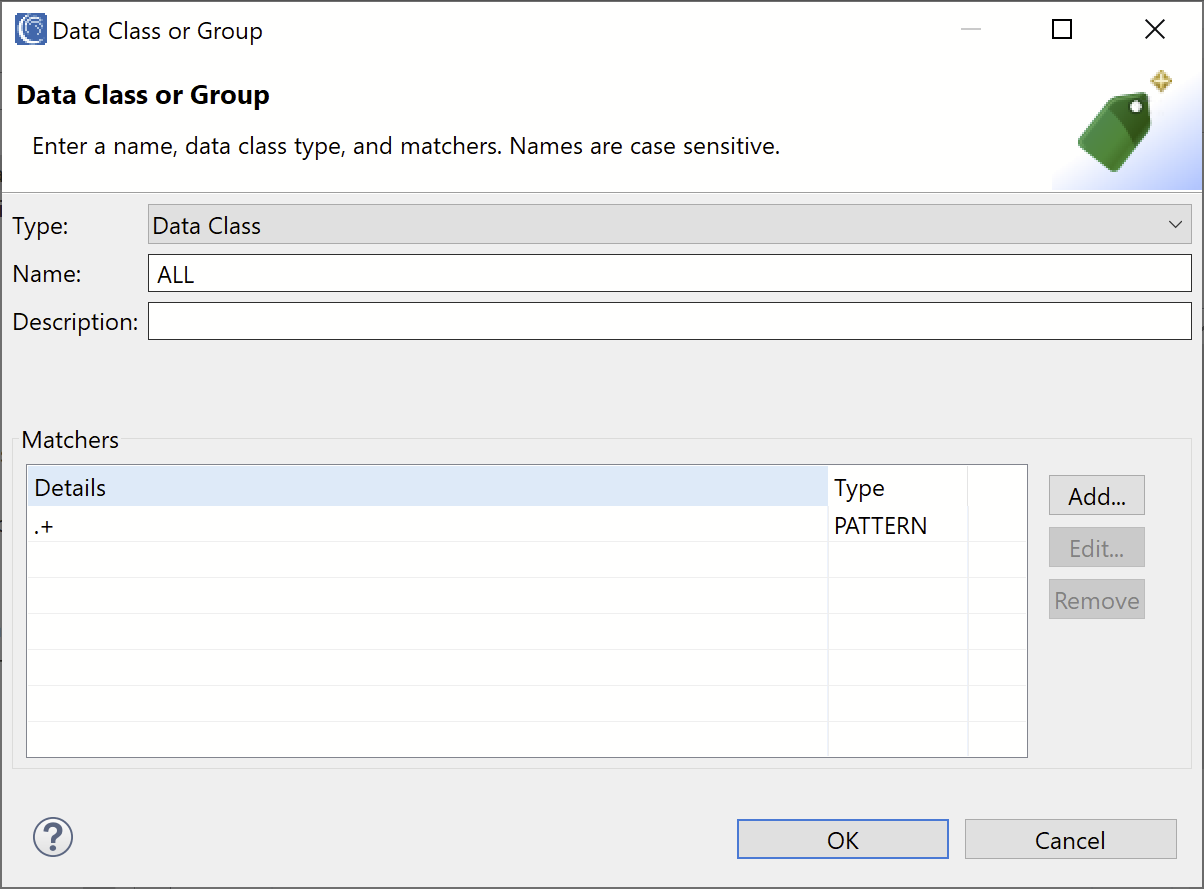
Let’s create a Data Class that will match on all data that it encounters. Click on Add to add a new Data Class Matcher to our Data Class. In the Type field, select Pattern and in the Details field enter the pattern “.+”.
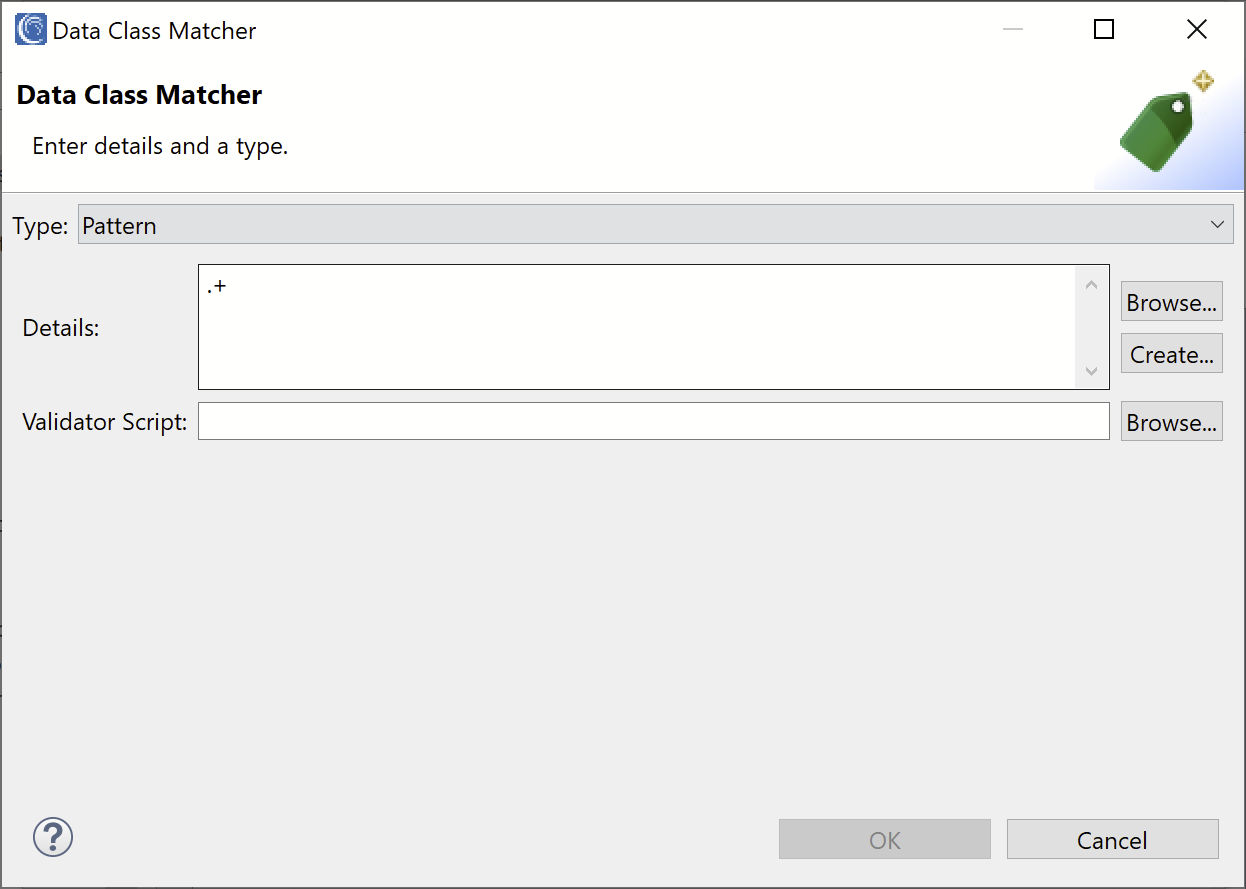
Click OK to create the Data Class Matcher, then in the Name field of the Data Class enter the name “ALL” to signify this Data Class will match on all data. Click OK to create the Data Class.
By itself, this Data Class is not very useful, since it will match and mask all of the contents of the table. To limit the scope of the Data Class to the “names” column, in the Filters field click Add to create a new filter.
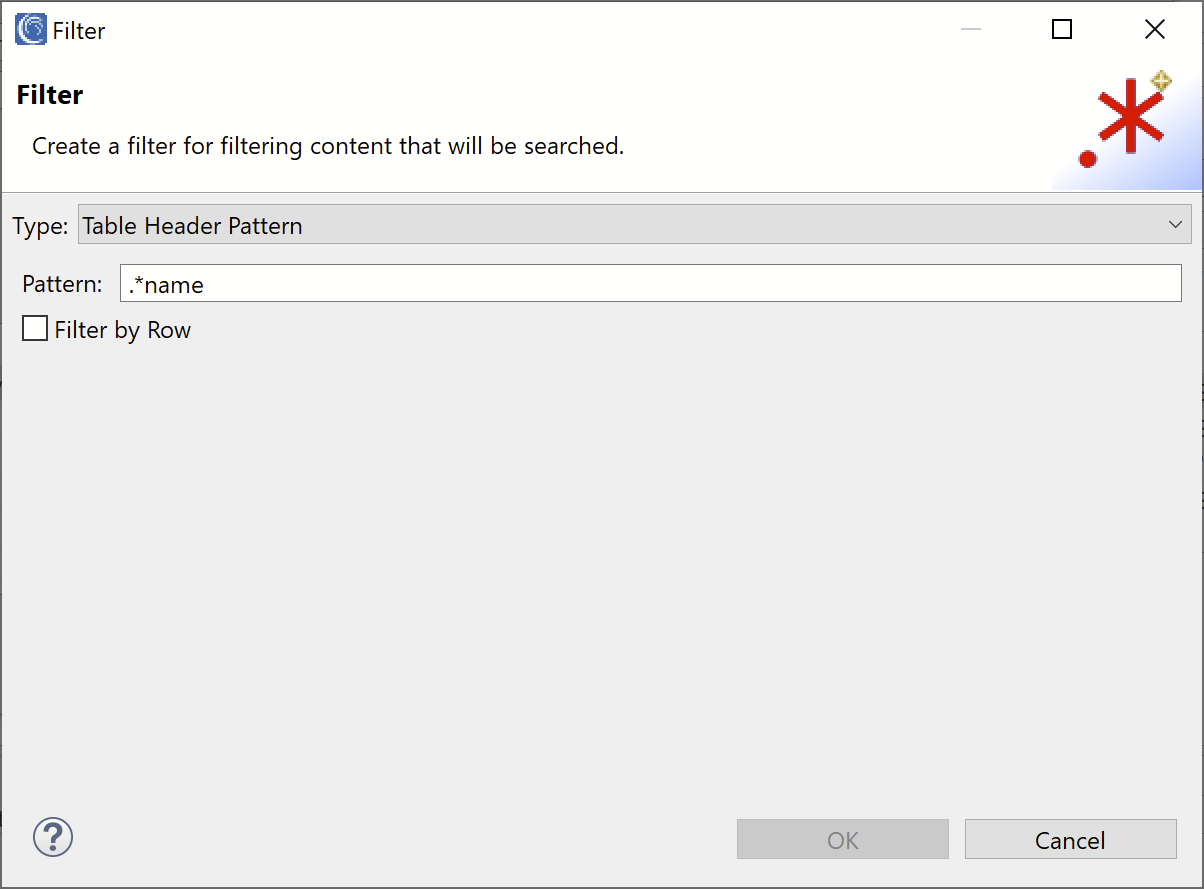
In the Type field, select the Table Header Pattern option to allow for filtering on table header columns. In the Pattern field, enter the regular expression pattern “.*name”, which will filter on any column which ends with the text “name” (for example, “first_name”, “last_name”, or “name”). Click OK to add the filter.
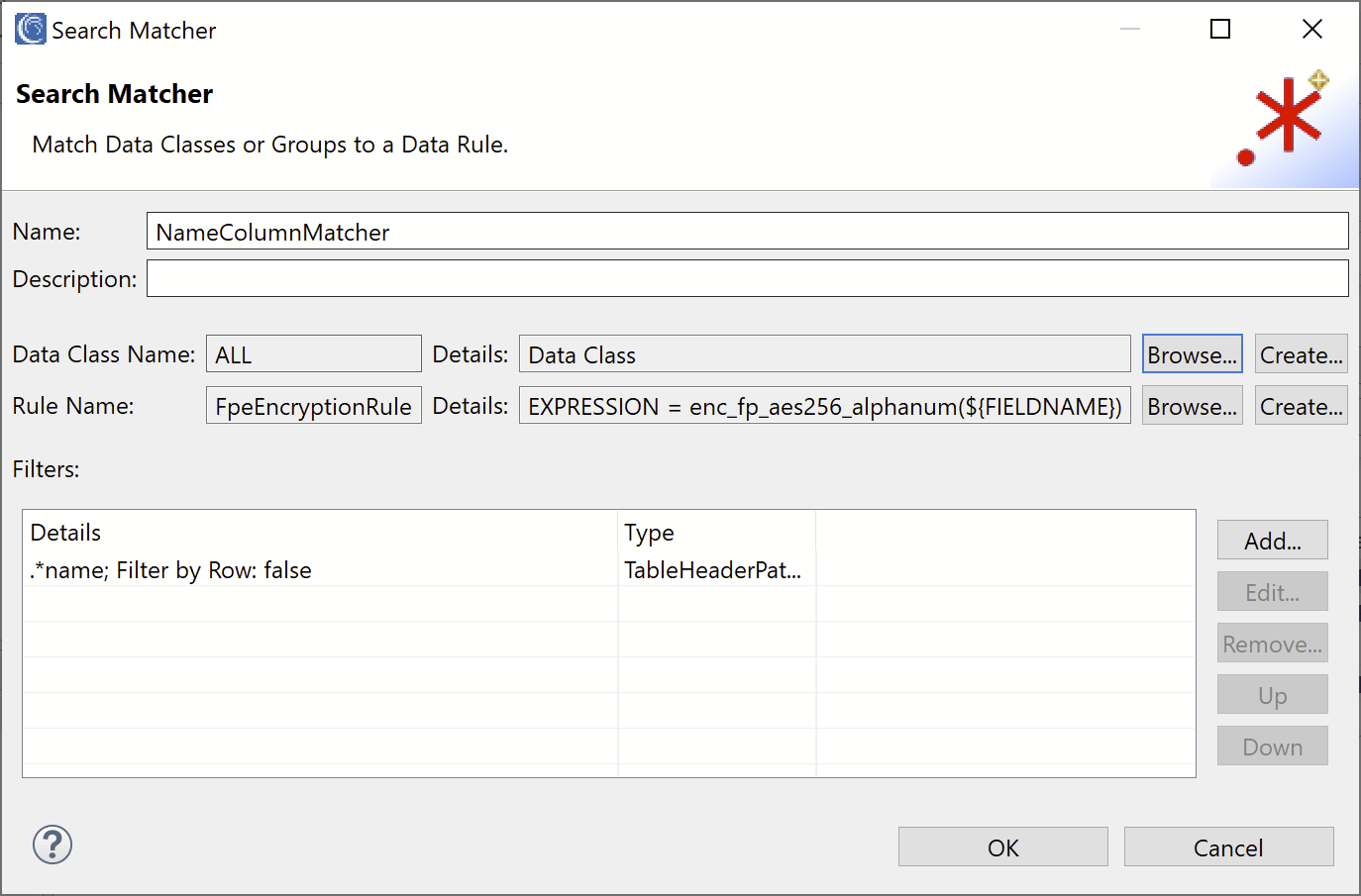
Finally, select or create a Data (Masking) Rule to apply to the names. For this example, we selected the Format Preserving Encryption rule. Your final Search Matcher should look like this:
EmailMatcher
Click Add to open the Search Matcher Details dialog. In the Name field, enter the name “EmailMatcher”.
Much like the “names” column, the “emails” column can be handled by a combination of the ALL Data Class and a Table Header Pattern filter that filters on email columns. However, email addresses have a unique structure which makes them very easy to match using a regular expression pattern.
An additional advantage of using the pattern is that emails are not limited to being found in 1NF columns, and can also be found in free-flowing text or other embedded documents, like the “notes” column.
IRI Workbench ships with an EMAILS Data Class. Use it in the Data Class Name field by clicking Browse and selecting EMAILS from the dropdown.
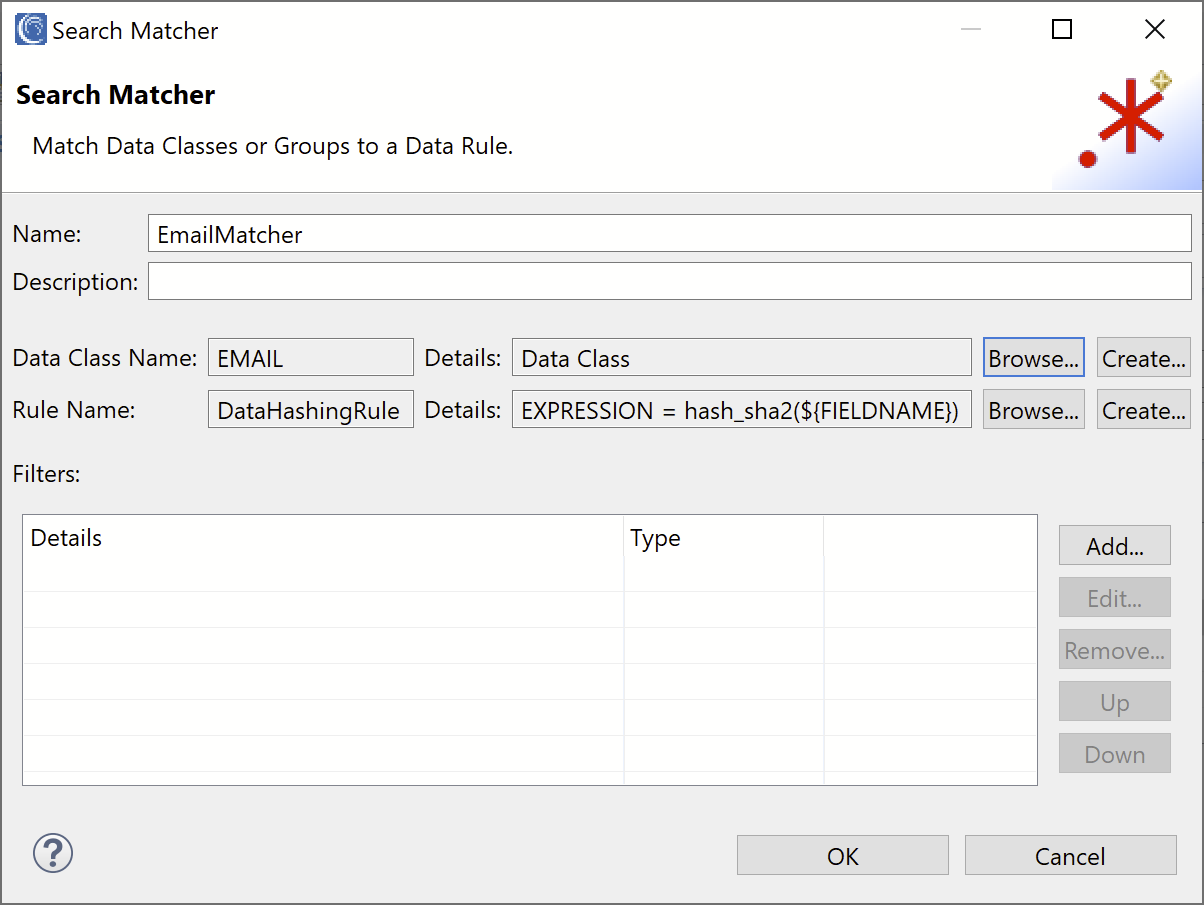
Finally, select or create a Data Rule which will be applied to the emails. For this example, we selected a sha2 Hashing rule. Your final Search Matcher should look like this:
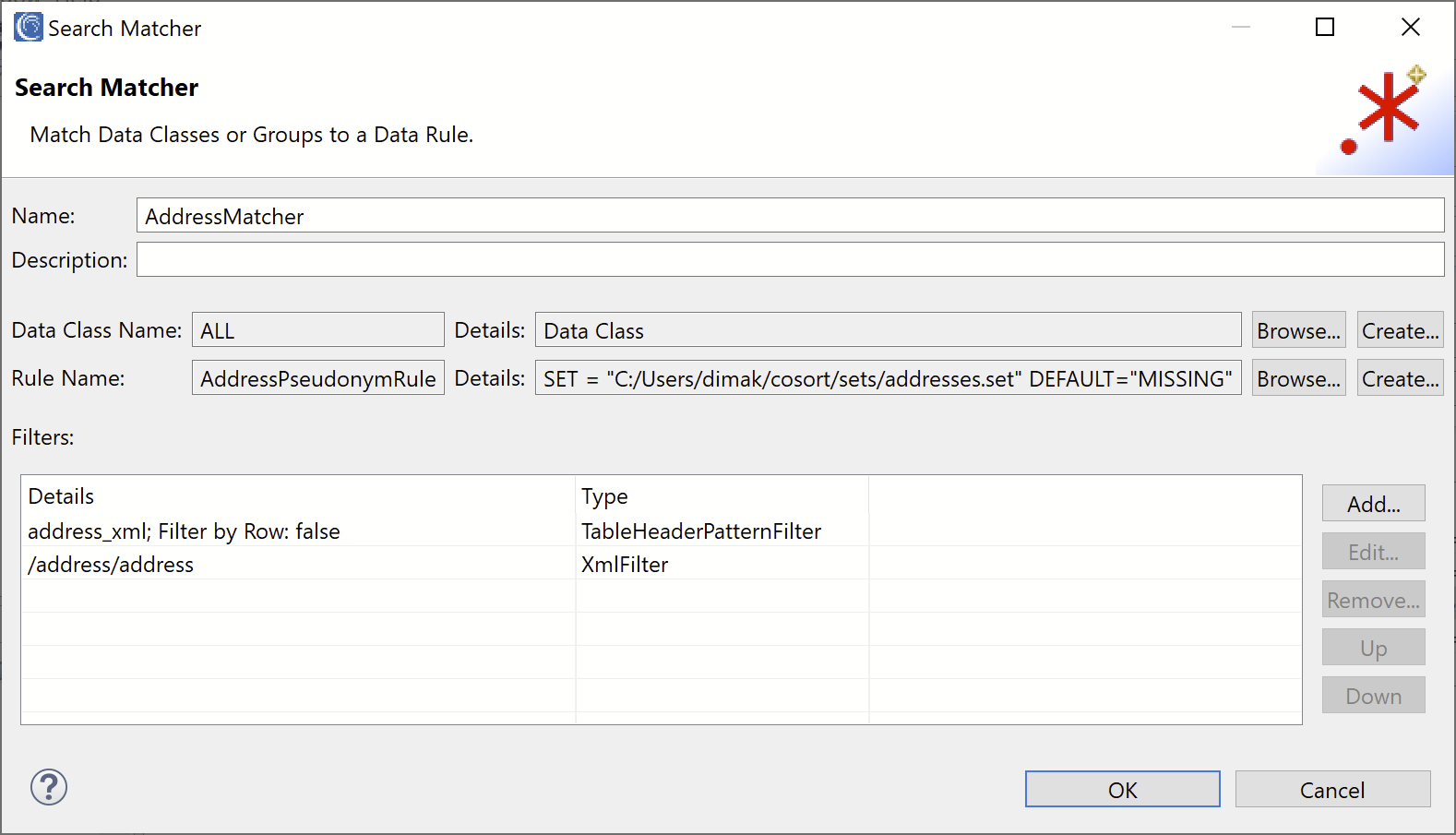
AddressMatcher
Click Add to open the Search Matcher Details dialog. In the Name field, enter the name “AddressMatcher”.
The address column in our source table contains XML data which details the address information, like the following example:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <address> <address>3516 Annabelle St.</address> <city>Fort Washington</city> <state>Maryland</state> <zipCode>33987</zipCode> </address>
While this would be a trivial exercise if we had a set file containing a list of matching addresses to find and mask, this information may not be easily available. Instead, we will use the structure of the XML to find and mask the address tag.
In the Data Class Name field, click Browse and select the ALL Data Class which you created for the NameColumnMatcher.
In the Filters field, click Add to create a filter. In the Type field, select the Table Header Pattern option to allow for filtering on table header columns. In the Pattern field, enter the regular expression pattern “address_xml”, which will filter on any column which matches the name “address_xml” exactly. Click OK to add the filter.
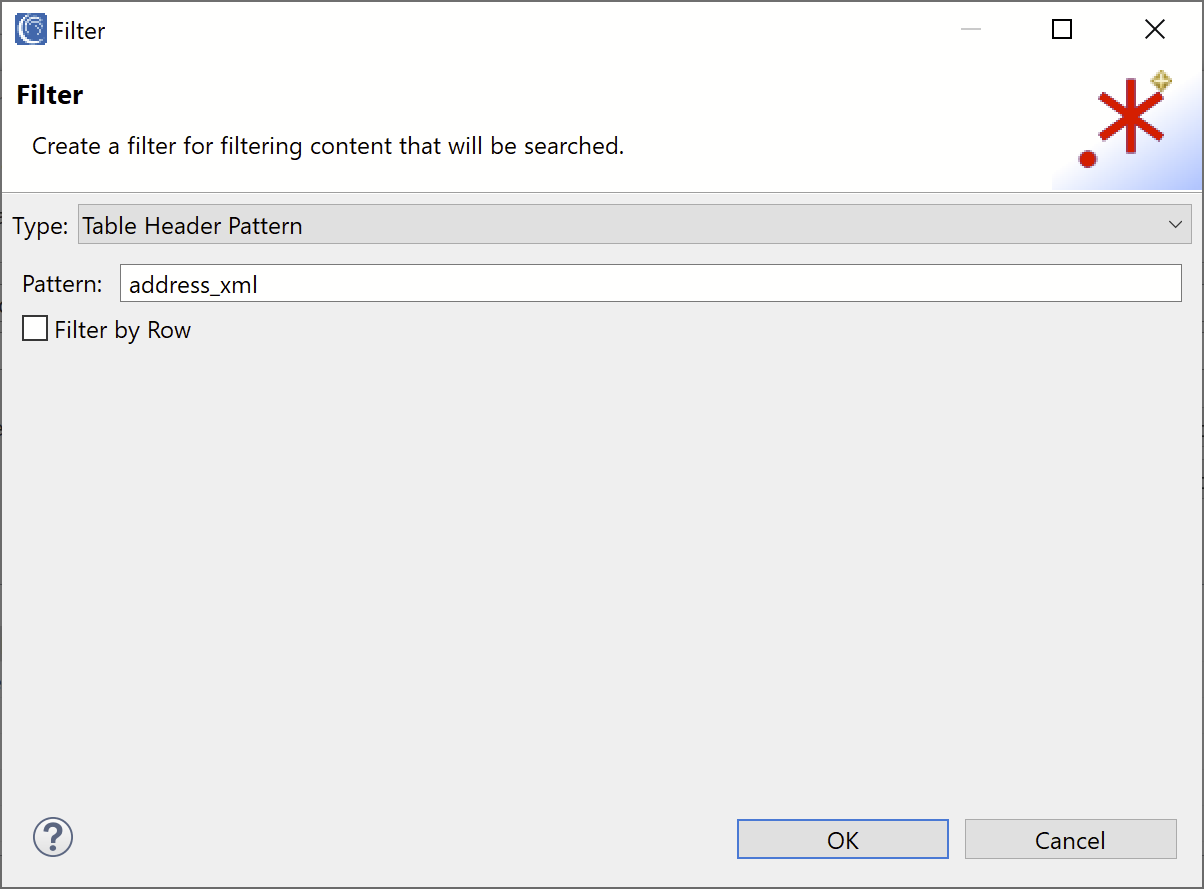
The table filter alone will allow us to mask every tag and attribute within the address field. If we wanted to only mask a specific tag, we can add an additional XPath filter.
In the Filters field, click Add again to add another filter. In the Type field, select the XML option. In the XML Path field, enter the XPath “/address/address”. To learn more about XML and other path filters, please refer to our article on DarkShield filters.
Finally, select or create a Data Rule which will be applied to the addresses. For this example, we selected a pseudonym rule which selects a random address from a set file. Your final Search Matcher should look like this:
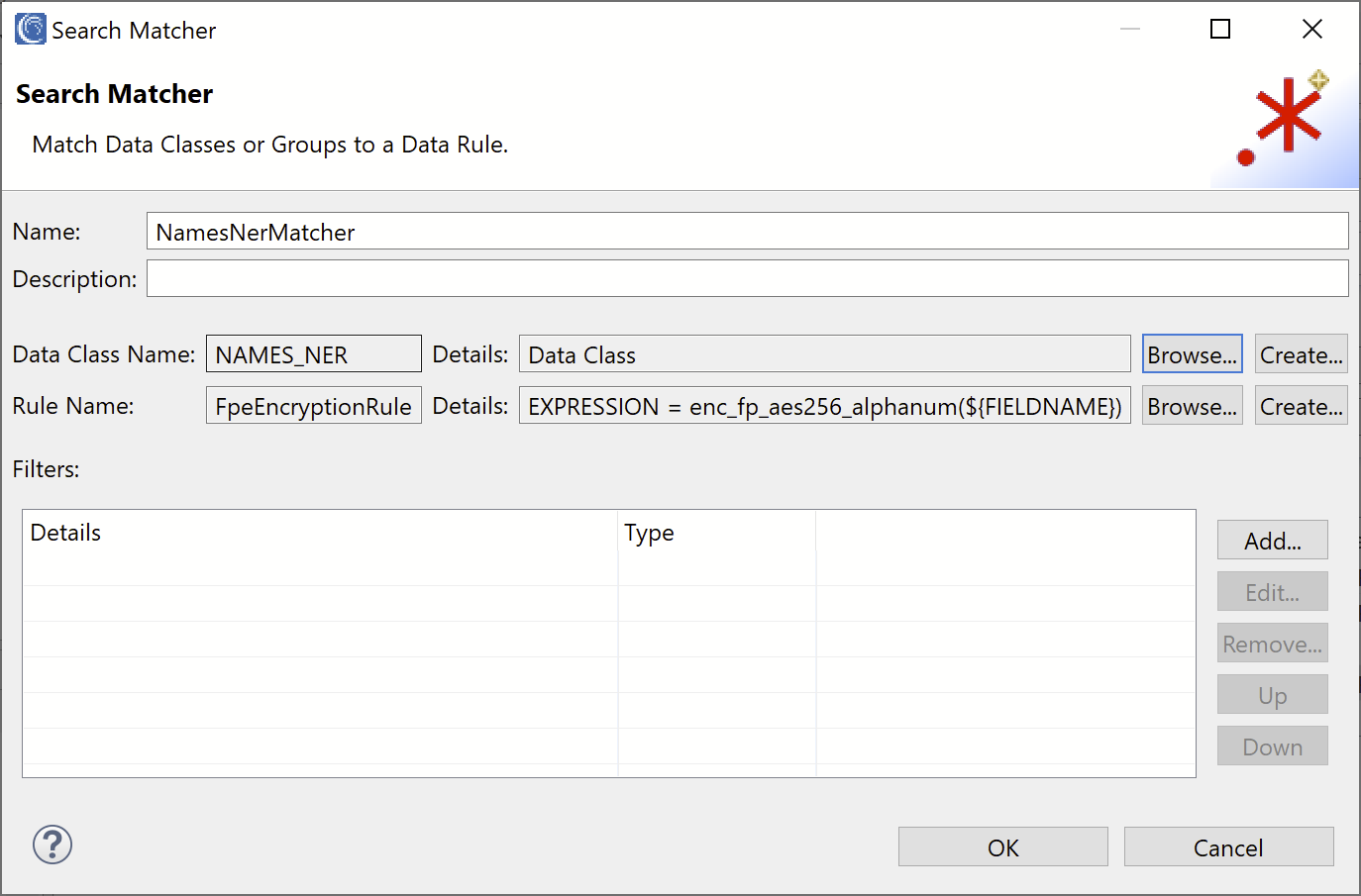
NamesNerMatcher
While the email addresses will be matched by the EmailMatcher, we need a way to match the name using the structure of the sentence. For that, we can use a Named Entity Recognition (NER) model trained on finding person names. Learn about NER in DarkShield in this article (coming soon).
The last column in the table contains a simple, free-text notes field in this sample format:
Hello, my name is {NAME} and my email address is {EMAIL}.
Click Add to open the Search Matcher Details dialog. In the Name field, enter the name “NamesNerMatcher”.
In the Data Class Name field, click Create to create and save a new Data Class or Group in the global IRI Preferences.
In the Matchers field, click Add to create a new Data Class matcher. In the Type field, select NER Model. Click Browse and select the path to the NER model which you can download here.
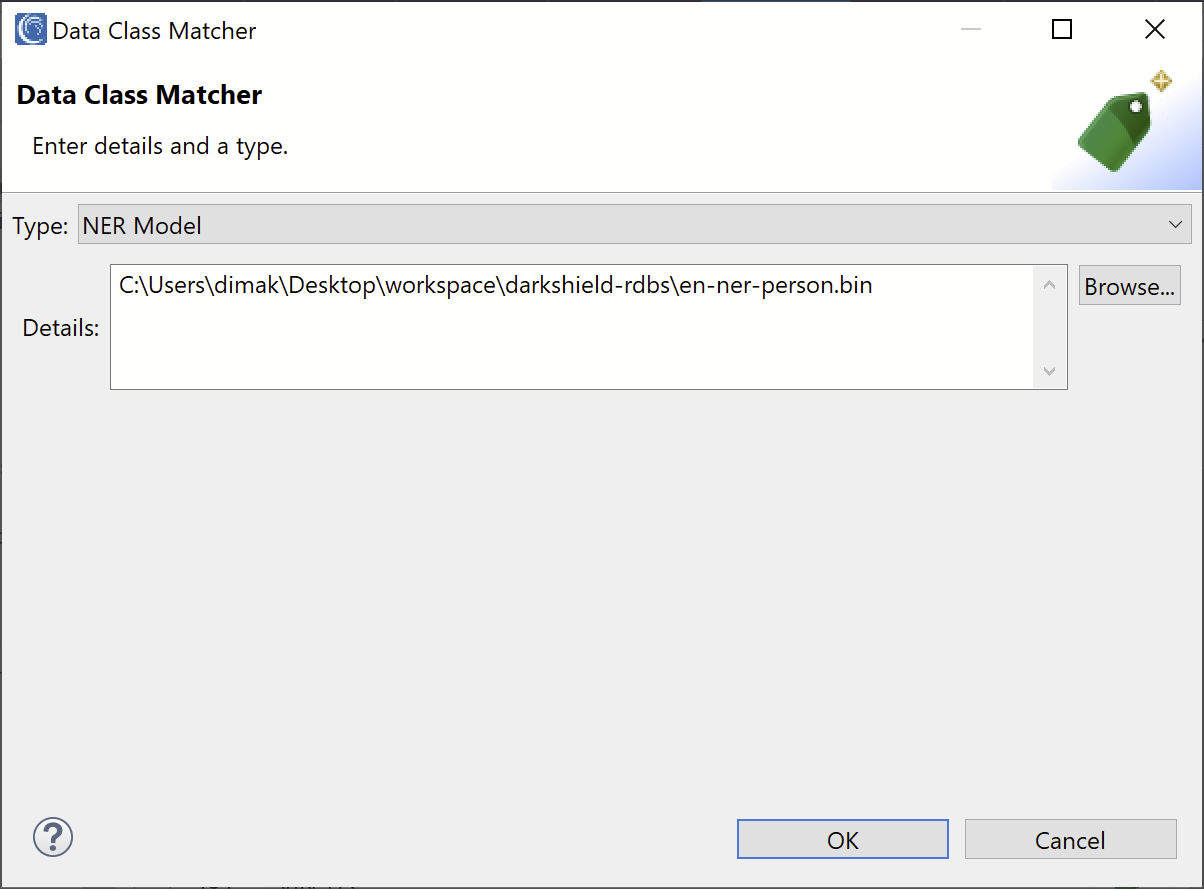
Click OK to add the matcher. In the Name field, enter the name “NAMES_NER” and click OK to create the new Data Class.
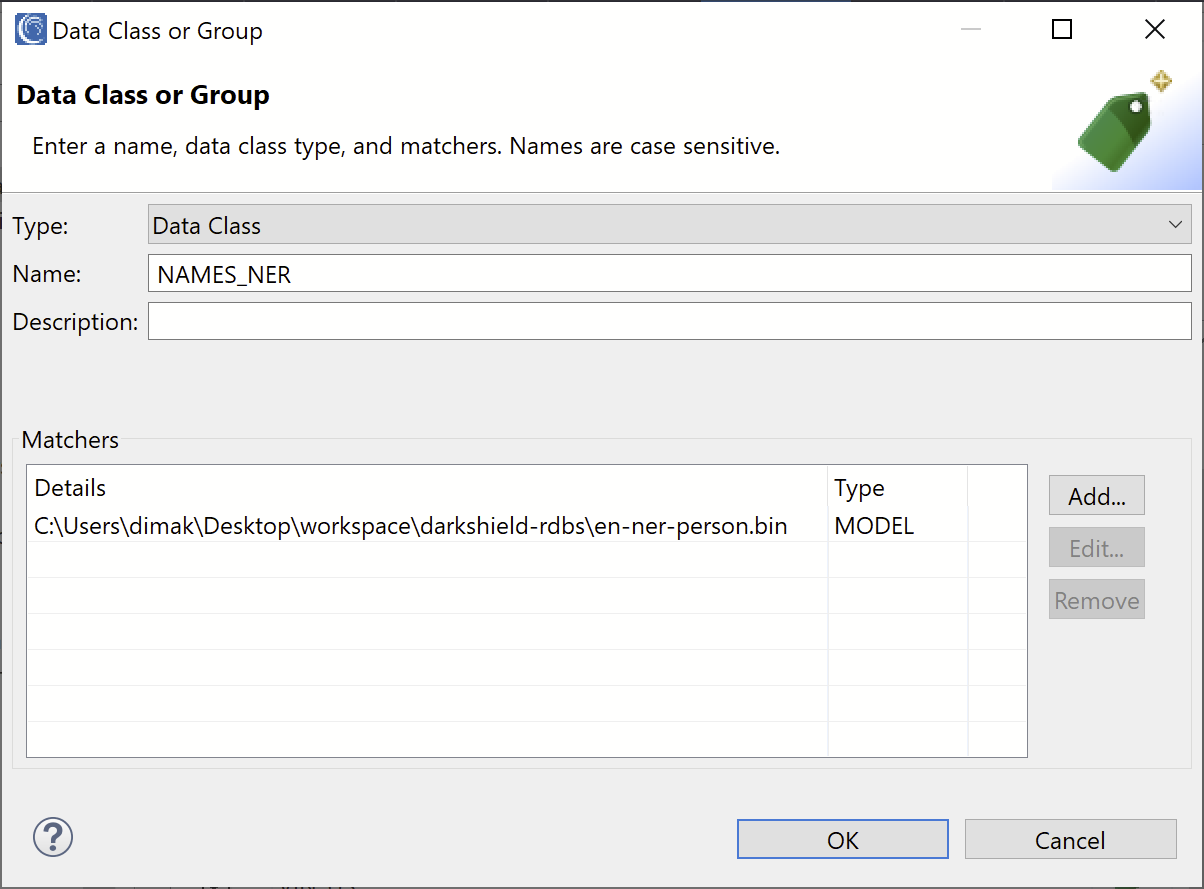
Finally, select or create a Data Rule which will be applied to the names. For this example, we selected the same Format Preserving Encryption rule which we created for the NameColumnMatcher. Since the encryption rule will generate the same unique ciphertext for the same name, we will see its ability to preserve referential integrity across multiple columns.
Your final Search Matcher should look like this:
Finishing Up
All of our Search Matchers should now be created, and the Search Matchers page should show:
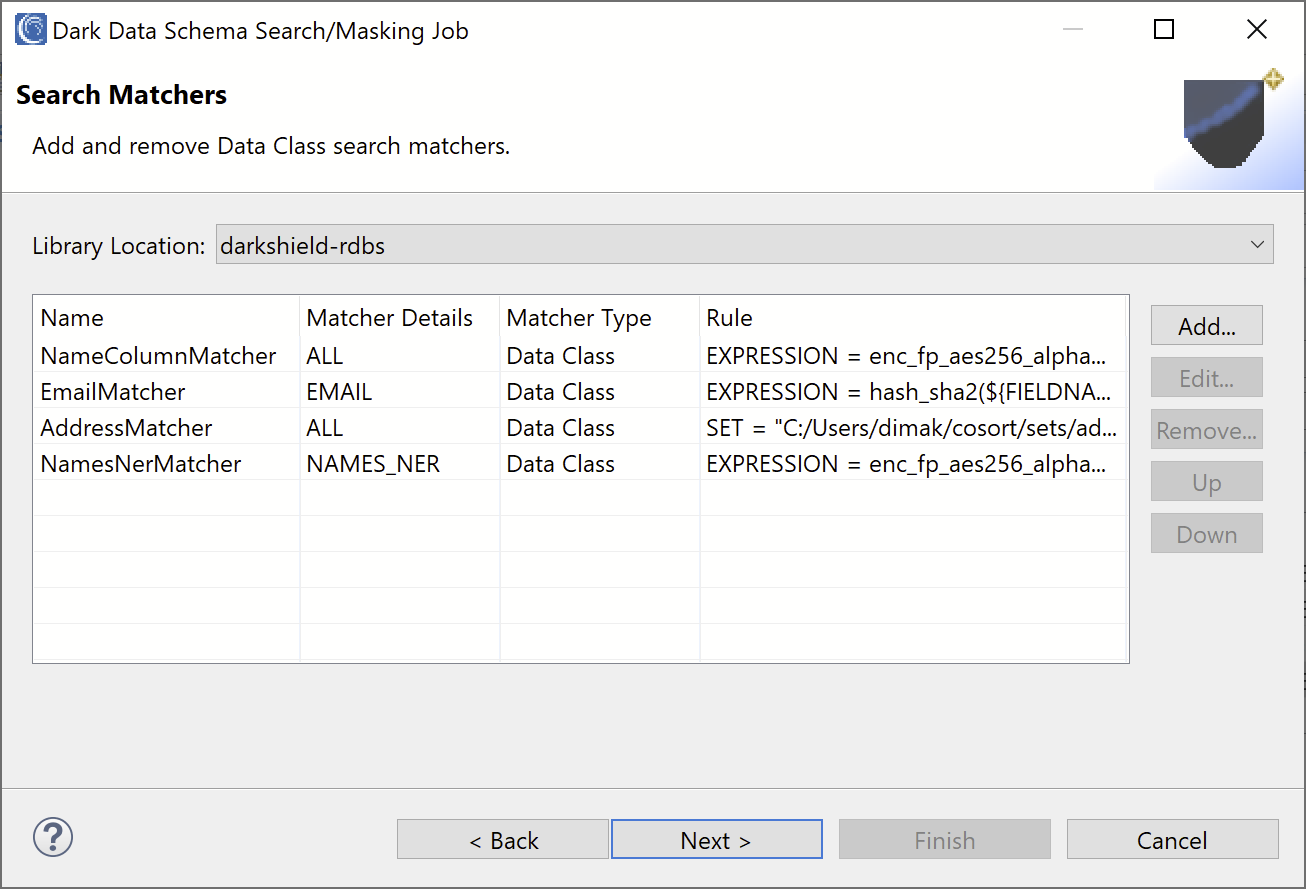
Click Next to proceed to the PDF Configuration page. As mentioned in the beginning of the article, DarkShield is capable of searching and masking PDF documents, so these options can be configured for cases when DarkShield encounters a PDF document embedded inside a BLOB column.
You can safely skip this page, since we don’t have any PDF documents in our current example. Read more about PDF-specific options in DarkShield in this article (coming soon).
Click Finish to generate the .search configuration file for our job.
Execution and Results
To execute the search and masking job, right click on the generated new_schema_search.search file from the project explorer, and select Run As -> IRI Search and Masking Job. A new_schema_search.darkdata file containing a list of search results in each searched table will be generated once the search and masking job completes:
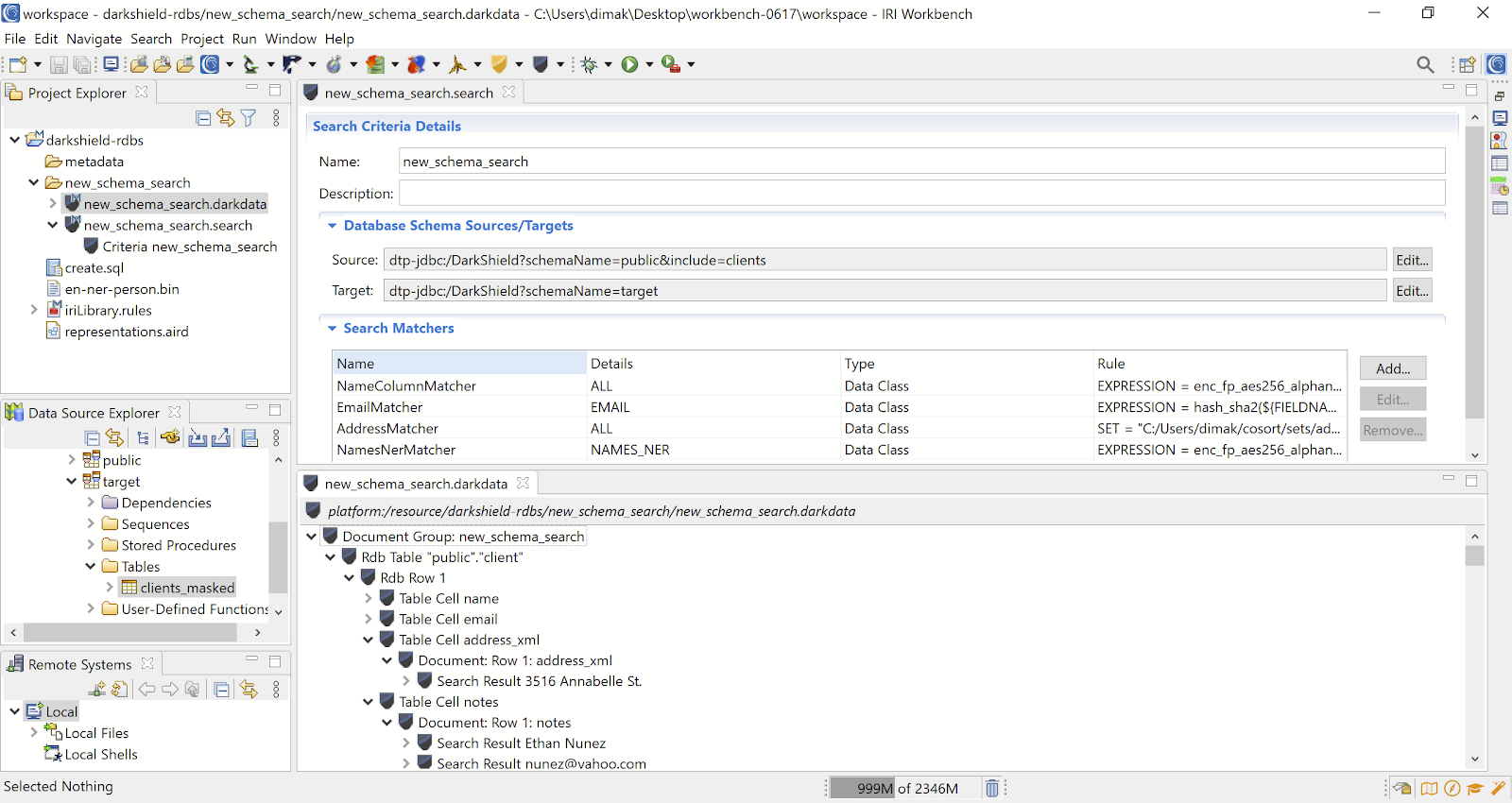
You can also compare the results between the two tables in Workbench by opening and viewing their sample contents (or selected Edit as I did) from the Data Source Explorer:
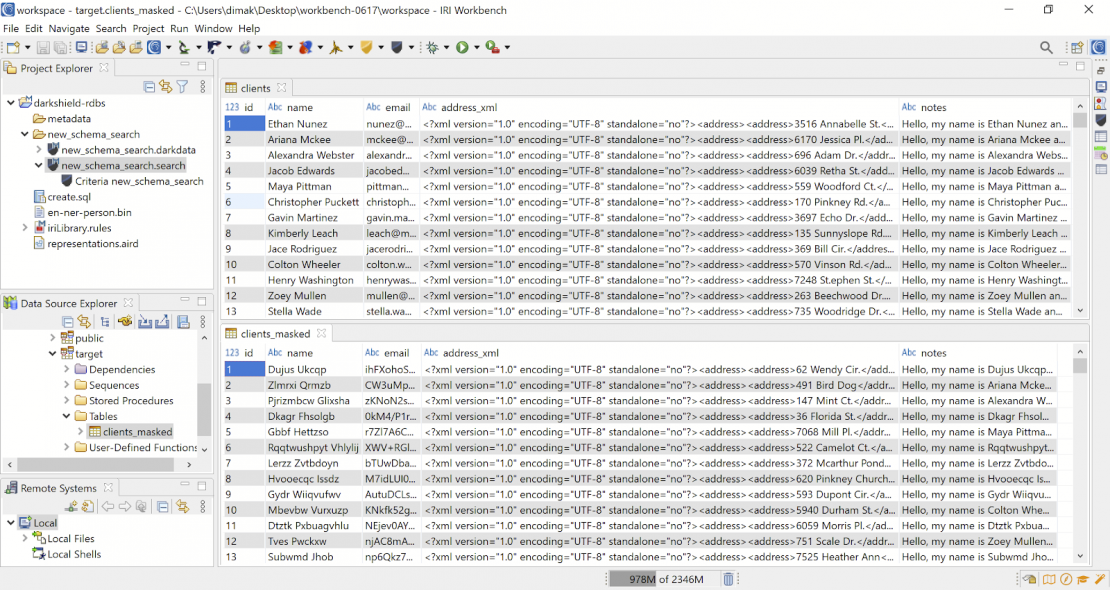
Note how all the values in the names column were encrypted (with FPE) the same way they were in their floating location in the notes column. The email addresses were hashed, and the addresses in their XML tag were pseudonymized through a random pull from our set file of external address values.
Please contact darkshield@iri.com if you have any questions or need help with your POC.